HIGH-PERFORMANCE MODEL SERVING
Inference endpoints are a way to provide external applications a realtime prediction API. For example a website could get the realtime product recommendation based on the current browsing history. Our model server is scalable and resilient and has no upper performance limit and no cold-start delays.


The whole point of Lentiq is to allow you to put things in production without any help.
Point and click baby. And API calls of course.
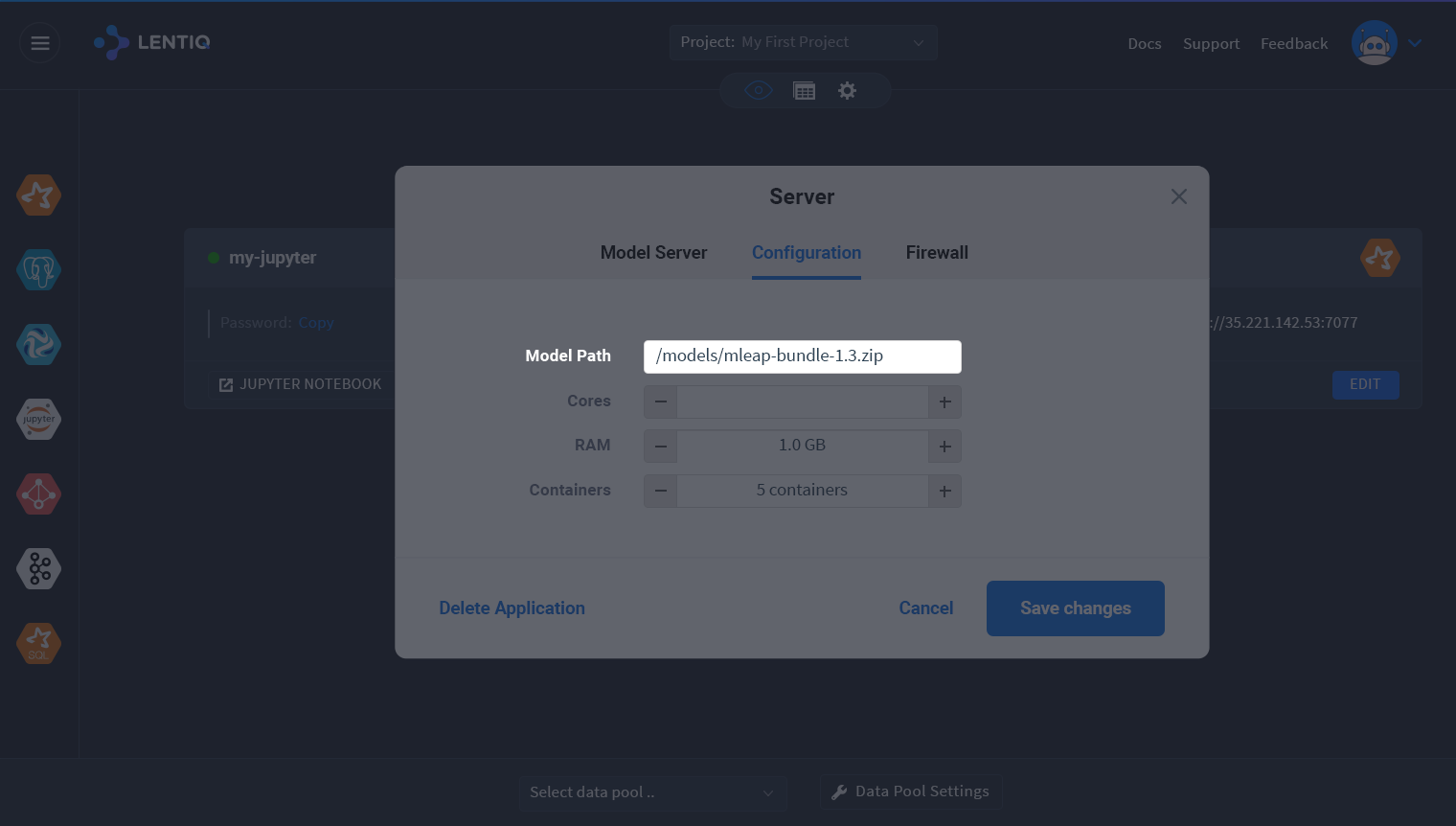
In Lentiq multiple instances of the model server are started at the same time and requests are loadbalanced between them. You can have hundreds of instances running for unlimited req/s.
If one instance fails, or a node goes down it's restarted on another node. If the model gets updated the new model will be loaded using rolling restart.

Most "serverless" model serving services out there need to boot up their instances before they can deliver a response to an API call if the API calls are not frequent enough to keep it alive. In Lentiq there is no such thing.
We support MLeap model format which allows us to execute models trained for Spark, Scikit learn and Tensorflow.