There are loads of brilliant resources on ML and data science pretty much everywhere these days. Unfortunately, most of them only look at how ML algorithms like RandomForest or LSTMs work and how to use them, and rarely address how to get the data, what and how many people you need in your team, for how much time, how much they cost, what tools they need, what databases, and so on.
ML is not black magic, it’s not more mystical than an equation predicting the value of y given an x. There is no reason why you, as a cunning entrepreneur, would not be able to use it.
Step 0: Figure out what you want to do
Think of ML strictly as a tool and nothing else. Trust me, doing ML just because it sounds cool is a bad idea. However, you can do many new things with a tool that can:
Learn by example and replicate a human
You show it a bunch of examples (like insurance claim texts, scans of invoices, pictures of kittens, etc.) and the decision that a human made and it will try to replicate the same decision on its own. Think about what areas of your business could be automated like that. Is there any decision that is tedious and needs to happen often and on a regular basis that you could at least partially delegate to a machine? It doesn’t have to be all or nothing. The algorithm can be built to defer to a human if its certainty level is below a certain threshold.
Discover (hidden) correlations and patterns
Give it multiple seemingly unrelated data sets and it can figure out which are correlated with which, and in what way. For instance, the hour of the day correlated with the dropping of sales. Even though correlation does not imply causation, it is still useful to know if it exists. This way, you can either track down why something weird is happening or use it to make predictions or improve your services. This is what they talk about when they say “discover insights” or “advanced analytics”.
Predict things
Technically, this is the same process as learning by example + discovering hidden correlations but it is important to state separately that these algorithms can “predict” the future with greater accuracy than polynomial models (that draw a line or a curve to approximate data in Excel). They can determine, if they have the necessary data, if there is a correlation between, for instance, certain sports events and the sale of red socks and, ultimately, take that into account when predicting your socks stock level.
So think about this: Can you improve something in your business with this tool? What is your low-hanging fruit?
Step 1: Figure out what data you have that helps in what you want to do
You have more than you think. If you’ve been using external SaaS services (Google Analytics, Gmail, Salesforce etc.) the data there is yours and you can use it along with your internal data.
If you feel there is enough data for a human to make a prediction, chances are the ML system will be able too.
Step 2: Get somebody in charge of the project
In reality, it is better if you do it yourself as you have both the will and the authority to make it happen, but if you cannot spare the time, find somebody you can trust. You need somebody to push things more than once for the project to be successful:
- Convince the IT guys to release the data or part of the data to this project.
- Coordinate the dev, data scientist, data engineer or any other person in the data team.
- Coordinate the putting in place of a prototype and the move to production.
- Coordinate the incremental improvements towards a useful system.
Step 3: Build your data “team”
Data teams typically consist of a “data scientist”, a “data engineer” and somebody (or access to somebody) with domain-specific knowledge. You can make do without the data engineer if you use the right services (such as Lentiq, of course) but you do need at least a developer that can learn a bit of ML.
You have 3 options from the most expensive to the most affordable:
1. Get outside help. There are many consultancy companies that can help. Ask around. This is the quickest method to get started, but for the long run I would go with #2 or #3.
2. Hire. This is a better option than #1 because these projects are not fire and forget kind of projects. They need to be constantly improved over time so permanent talent is useful if you can afford it. It’s closer to a website than to an ERP system.
3. Train existing staff. If neither of the above is plausible you can choose to give your existing staff new business cards:
- Data Scientist: It is easier to convert a developer than a business analyst. You do much more programming than you would think. It’s not complicated production-level programming but programming nonetheless. In case you are wondering, Python won the war for data science, and Pandas, pySpark and Keras/TensorFlow are the most used frameworks nowadays.
- Data Engineer: Pretty much every good ops/sysadmin should be able to pick up how data flows in a big data pipeline. You don’t need DevOps skills. This is a very different technology stack, Spark and Kafka being the most important.
Step 4: Get your data in one place, into a system designed for these types of operations
Don’t even think about running this kind of analysis on production systems (like a MySQL server). It is impossible due to the strain it will put on your servers which will affect your day-to-day operations. ML training takes a lot of resources for a short amount of time (a few hours each month) which is why using separate, on-demand cloud resources is by far the most economical way of doing ML.
There are three ways to go about doing these kinds of analysis:
- Use your data scientist’s laptop. While this is certainly possible for many scenarios given the monster laptops out there, you won’t be able to properly train the model periodically on new data and you’ll probably get what’s called a model drift. She’ll also spend so much time installing stuff and dealing with python libraries issues that it’s just not worth it.
- DYI in a cloud provider like Amazon or Google, as they provide some very powerful tools like Sage Maker. However, you will need somebody good enough to work with this kind of solutions. They are powerful but also complex.
- Use a SaaS service. This is where Lentiq comes in with its “mini data lakes”. These mini data lakes are designed specifically for short-handed teams that are just getting started. They are also designed to be cost-effective.
Step 5: Prototype
Depending on what you choose to do: for advanced analytics or an ML-based production system you need to start small and test your initial assumptions about the feasibility of the whole thing. Don’t worry, you can still shut everything down at this point if it doesn’t make sense or you can shift your team’s effort to something else.
Step 6: Go to production
This is where most initiatives fail. Going into production is more complicated than it seems. With Lentiq you’ll find it’s easier than most other solutions to easily automate analysis or model training but you still need to do some work on the production systems as well (i.e. your website or back-office systems). You’ll need to think about it well in advance so that you can book development resources, as well as talk to your sysops beforehand to have a proper go-to-production plan in place.
How will it be tied into my production systems?
You will need to put data into the data lake, use it to prepare and train the prediction models, and provide production systems with what’s called an Inference API (also called model serving). For instance, if your model is a recommender engine, you will submit the users’ viewed products and get back a 'likelihood of purchase' prediction.
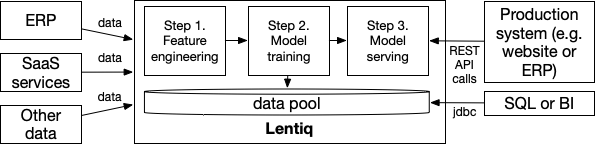
Another way of using your data pool is to simply query the data using a BI tool or SQL just like you would from any other database.
How much does it cost?
Obviously this depends on a lot of factors but I think it’s important to at least give you an idea, so here is a back-of-the-envelope kind of cost analysis for you:
The good thing about the cloud is that you can start small and grow or stop at any time. Just for reference, the typical enterprise data lake costs a good few millions, mostly due to the required staff and the amount of data. Also many enterprises fail to leverage their data lakes properly because they were built without a clear use case in mind, as well as due to too much red tape. If you build your mini lake with specific purpose in mind you’ll trump them all, even if you start later and with far less money.
How much time does it take to implement?
It takes a few weeks to get to the prototype stage (step 5) and a few months to progress to production. All-in-all around 3 months if everybody cooperates from the moment you have the staff. Remember that data-driven initiatives are not fire and forget. They’re not like an ERP or CRM that you just deploy. They’re more like an e-commerce website which needs constant updates and improvements. This is because when you get started, accuracy is less important, however, as you progress you’ll want to improve model accuracy and use ML for other situations as well. While it takes years to improve model accuracy to a practical maximum, the ML initiative will be paying for itself many times over by that time.
What’s my ROI?
It’s close to impossible to calculate an exact ROI beforehand. It’s one of the problems of big data in general so a leap of faith is required. There are a few examples though: 35% of Amazon’s sales come from its recommender system which works via the website itself and email, with the email’s conversion rate possibly approaching 60%. So if you sell things online you could try aiming for some marketing ROI increase or some other metric. For example, you could set a target of say 20% increase in email sales due to the ML system and then determine how much you can afford to spend on the ML project.
Conclusions - Set the right expectations
The ML system has more processing cycles and more memory than a person, so there are many situations where it will behave way better than humans would. However, it lacks contextual information and domain knowledge used so easily by humans so it will do poorly on tasks such as making sense of free text; it also has particular troubles with things like sarcasm. It’s not magic, it’s just math.
The hype around big data and AI, the Terminator and Matrix movies and the myriad of vendors all contribute to inflating the expectations from these technologies. Most initiatives fail not because the technology cannot do the job but because the job isn’t clear. People go into this approach without actually having a clear use case in mind, just because it’s “cool” to use AI and Big Data and because it can be a career-enhancing move. Without a clear goal, however, AI and ML are just solutions in search of a problem and are destined to fail.
You need to think more about this as with industrial robotics than home robotics. The sooner you do this, the clearer the path ahead becomes and you too can yield great benefits like the big guys. It’s crucial to set the right expectations for you and for your team. ML is just a tool and just like a hammer it needs a human hand to work its wonders.






