We are releasing several new features in our data lake as a service platform designed to help you put data projects in production faster and easier: a distinguished workflow manager, a reusable code blocks system and a model server.

Read about our company, how we work and the latest developments in the industry.
We are releasing several new features in our data lake as a service platform designed to help you put data projects in production faster and easier: a distinguished workflow manager, a reusable code blocks system and a model server.

If you browsed our website, you know by now that we are focusing on providing an integrated experience for managing end-to-end machine learning and analytics pipelines that do not require advanced coding or system administration skills. Because we want to help make your job easier!
This release comes with a new menu in our UI that provides the ability to manage workflows, create reusable code blocks, and more, which we will detail below. But first…
Workflows help you automate, use and reuse already tested models and code making it easier for you to adapt to new or different clients or projects. Be it data ingestion that you need to do periodically, data deduplication, model training, data preparation or any data science tasks, workflows help you streamline projects and ultimately save you time. Since you can execute your workflows periodically, once you set up a workflow, you can relax and let it do all the heavy lifting for you.
Workflows are DAGs (Directed Acyclic Graphs) that can be scheduled to run periodically. They work on project-level in our data pools and are made out of tasks. These tasks are created from reusable code blocks. The reusable code blocks basically represent the foundation of a workflow and can be viewed as task templates (with params, or environment variables, and a docker image that is built automatically). Reusable code blocks should have specific problems/jobs* so that they can be easily interconnected in a more complex sequence of steps.
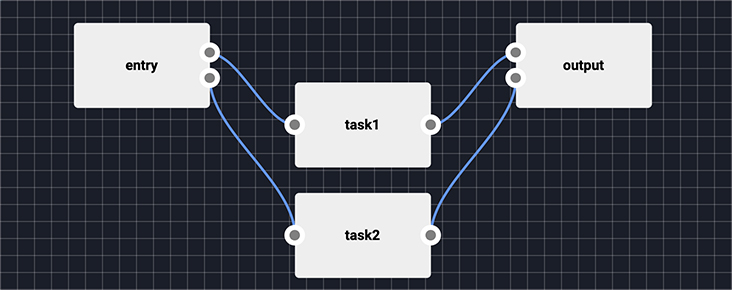
* think about ingesting a dump of a database in an object storage every night at midnight or running a retraining of a model on new data
Find out more about workflows in our documentation
They can be created automatically either from notebooks, which we call LambdaBooks, or from user-provided Docker images that pack custom applications and offer the flexibility and the possibility to capitalize on existing work.
Reusable code blocks are shared across the data lake and can be parametrized to be configured when they run as part of a workflow. This enables the workflow designers - data scientists or data engineers - to use the same code block in multiple projects and multiple clouds without changing the code. The only things that need to be changed are the project-specific parameters such as: configured resources per task, input and output parameters, connection information towards external applications, and so on.
Our reusable code blocks are preconfigured to use our abstraction layer which means they are fully portable in terms of access to data and compute resources, irrespective of the underlying cloud provider.
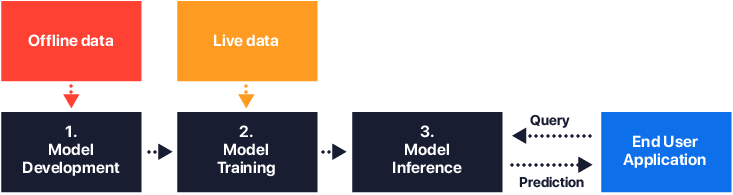
We are also releasing a model serving mechanism to help you serve a model to an external application. Integrating models into your existing applications that are being used by your end-users can bring incrementally a lot of business value in real-time and can contribute to the wow factor of your product and services. With our scalable and resilient model serving mechanism that uses the standard Mleap format serving models to 3rd party applications is extremely simple.

Learn more about managing models
With Lentiq, we provide even more features that enable collaboration among data teams. In a previous release, we have launched a feature that helps users share notebooks, helping organizations build an internal knowledge repository of best practices, model implementations and evaluation examples. Having the possibility to discover data through our unique Data Store, teams can kick-start new projects instantly, and a new team member's onboarding process can be cut by half.
With this new release, we bring notebooks closer to production and empower users to operationalize the knowledge available in the organization in the form of notebooks, curated data sets and executable code blocks, covering the missing link in productizing data science, thus making it easier to move to production. Once a notebook is published, it can then be used as a building block of an automated workflow that can handle data ingestion, model development, model training, or model serving processes.
Learn more about publishing notebooks
You can test our platform for free in a 14-day trial and see these features in action, what are you waiting for?






