But what is a data pool?
A data pool is an independent, isolated micro-data lake. A data lake includes at least one, but ideally many data pools that belong to the same organization, and are managed independently (they can even run on different cloud vendors!). While the administration and resource allocation are independent for each pool, they can communicate and share data and notebooks between them.
A data pool consists of a Kubernetes cluster that facilitates managing multiple data pool projects. Each data pool runs independently, and budget and resources are allocated considering the individual project's demands. Thus, costs are more predictable per project.
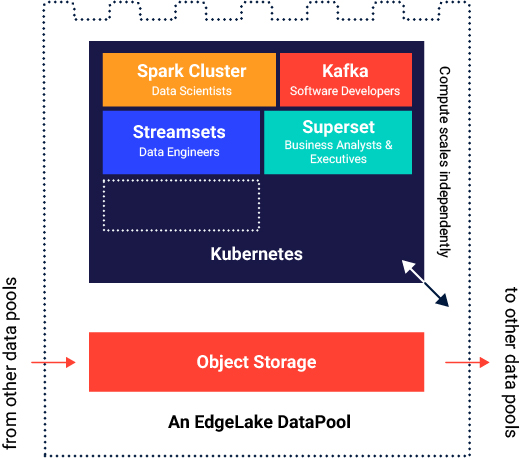
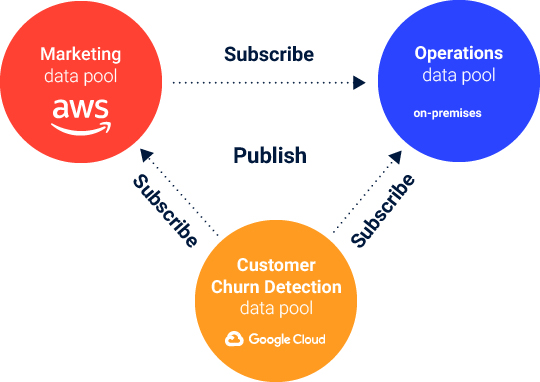
The data pool can be deployed in a specific cloud provider, of your choice, and can collaborate through the data sharing mechanism with other data pools inside the same organization. The governance rules are enforced only when sharing data with other data pools.
What is a data pool project?
A data pool project is an isolated collection of resources and data which is administered by users with access to that particular project. Each project has a specific quota that is set by the data lake administrator. The team members that have access to the project can use memory and CPU resources from the project quota for the applications they need to use.
By being isolated, the project quota is under control, since the applications in the project can’t exceed it without either freeing some resources or increasing the quota (which requires administrator intervention).
The data uploaded in a project is available only to users allowed to work on that specific project. All projects that need to share data across the entire organization have to put the files and tables through a “publish” process, and this is where the data governance rules are applied.
In terms of storage, each data pool project has an object storage bucket associated with it, and all data is isolated in that bucket. Only when data is shared, it gets replicated in a common object storage bucket as well.
To sum it all up, Lentiq’s greatest benefit is allowing data teams (be it data scientists, data engineers, software developers or business analysts) to use whatever tools they want, and whatever skills and resources they have in order to get the job done. All this, without having to answer to a centralized policy. Lentiq allows teams to mitigate infrastructure requirements and apply governance policies locally, thus enabling innovation and adaptability.
For more information on data pools, as well as on administrators, users and their roles, please see our documentation.






