Querying data with SQL (DataGrip)
Querying data using SQL is a basic but fundamental use of any data lake. Lentiq is compatible with most JDBC/ODBC compatible tools and uses Apache Spark's query engine.

The data is stored in parquet format in the object storage, the schema is stored a metastore database that is linked to Lentiq's meta data management system.
The query engine is SparkSQL which uses Spark's in-memory mechanisms and query planner to execute SQL queries on data.
1. Deploy the Spark SQL Application
From the Lentiq's left-hand application panel click on the SparkSQL icon.
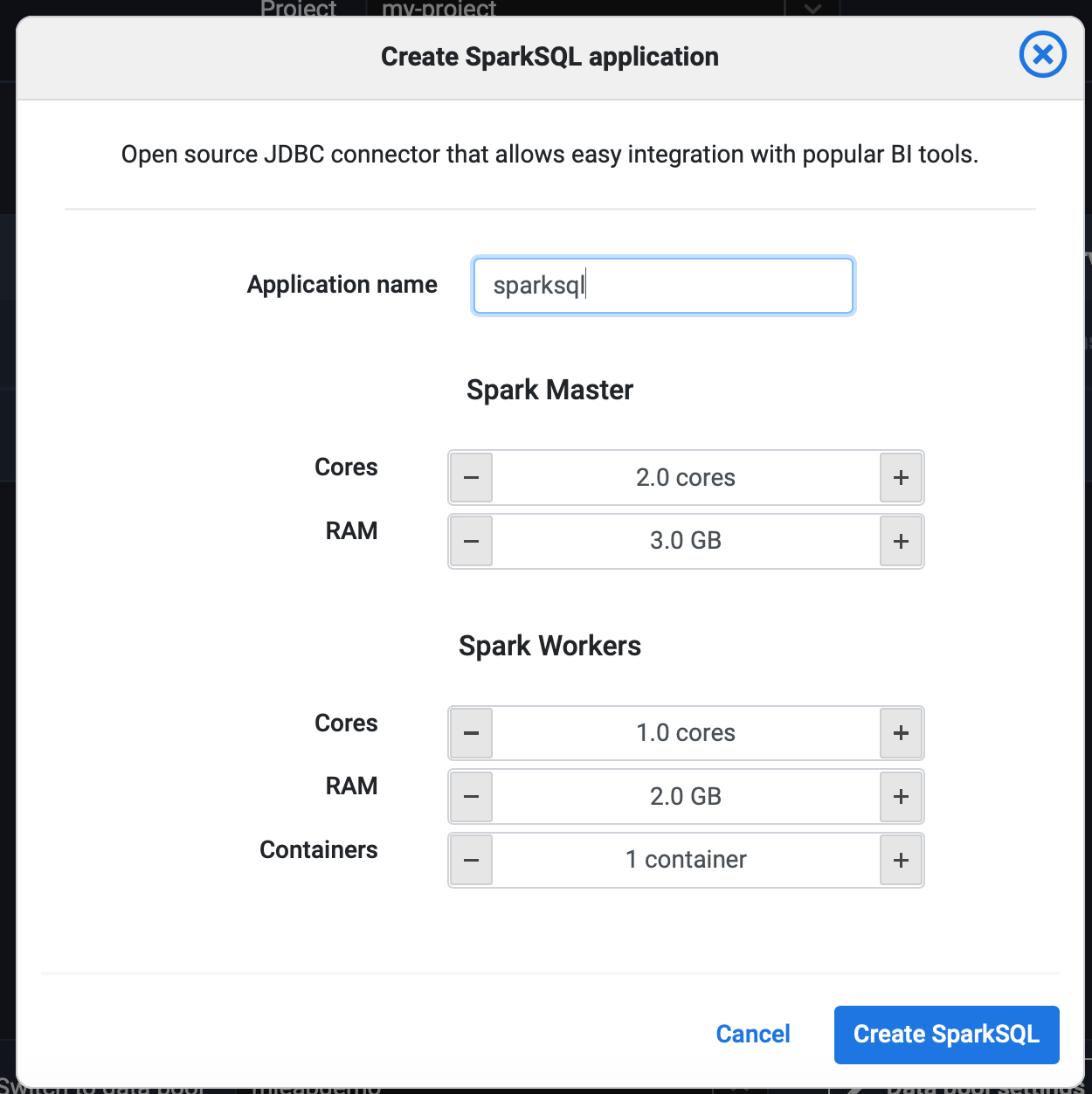
Click Create Spark SQL.
2. Download JDBC drivers
SparkSQL is compatible with Apache Hive's JDBC connector version 1.x. It also has a Hadoop-core dependency that does not come with it.
mkdir ~/jdbc-drivers #you can put these anywhere
cd ~/jdbc-drivers
curl -O http://central.maven.org/maven2/org/apache/hive/hive-jdbc/1.2.1/hive-jdbc-1.2.1-standalone.jar
curl -O http://central.maven.org/maven2/org/apache/hadoop/hadoop-core/1.2.1/hadoop-core-1.2.1.jar
3. Configure your BI tool to use the JDBC drivers
The JDBC connectors should work with all JDBC compatible clients. For the purpose of this demonstration we're going to use Jetbrains's excelent DataGrip.
- Click on the "+" sign and select "Driver":
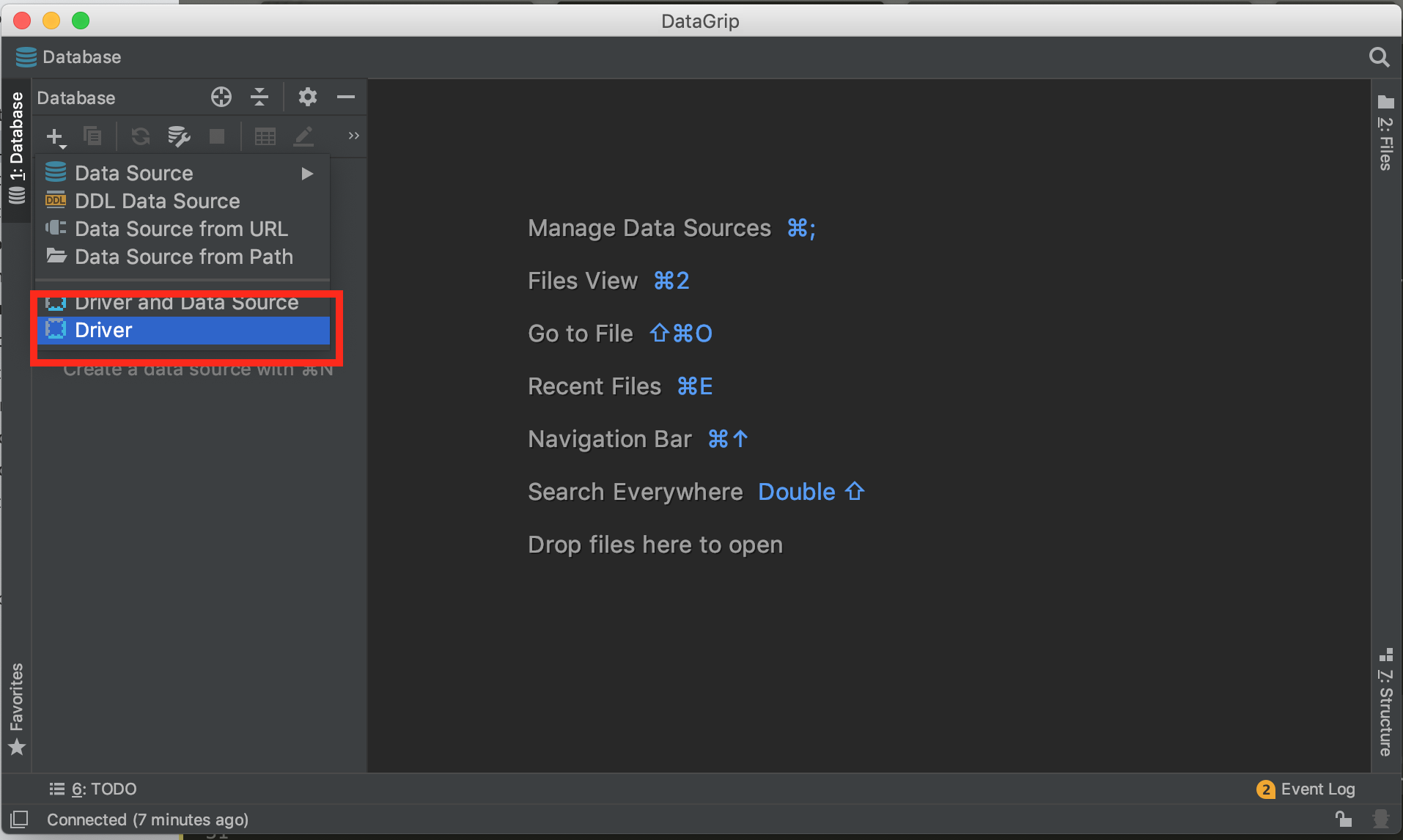
- Click on the "+" sign from "Driver files" and add both jars
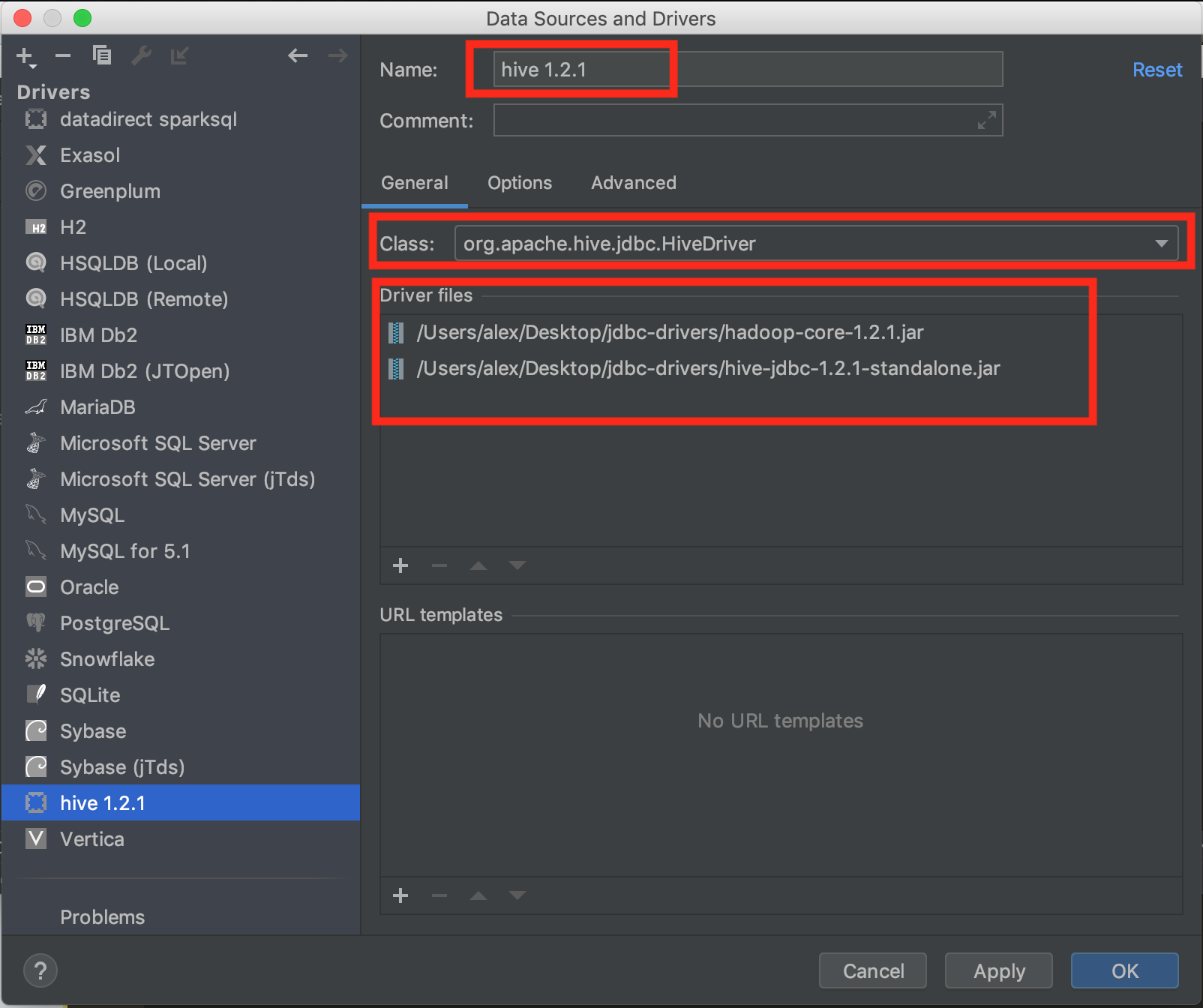
Rename the driver to "Hive 1.2.1"
Change the class to "org.apache.hive.jdbc.HiveDriver"
On the Options select the Apache Spark option in both Dialect and Icon dropdowns.
![]()
- Click OK
4. Create a database connection
- Click on the SparkSQL's Edit button and copy the JDBC URL. It should be in the form
jdbc:hive2://34.66.161.32:10000
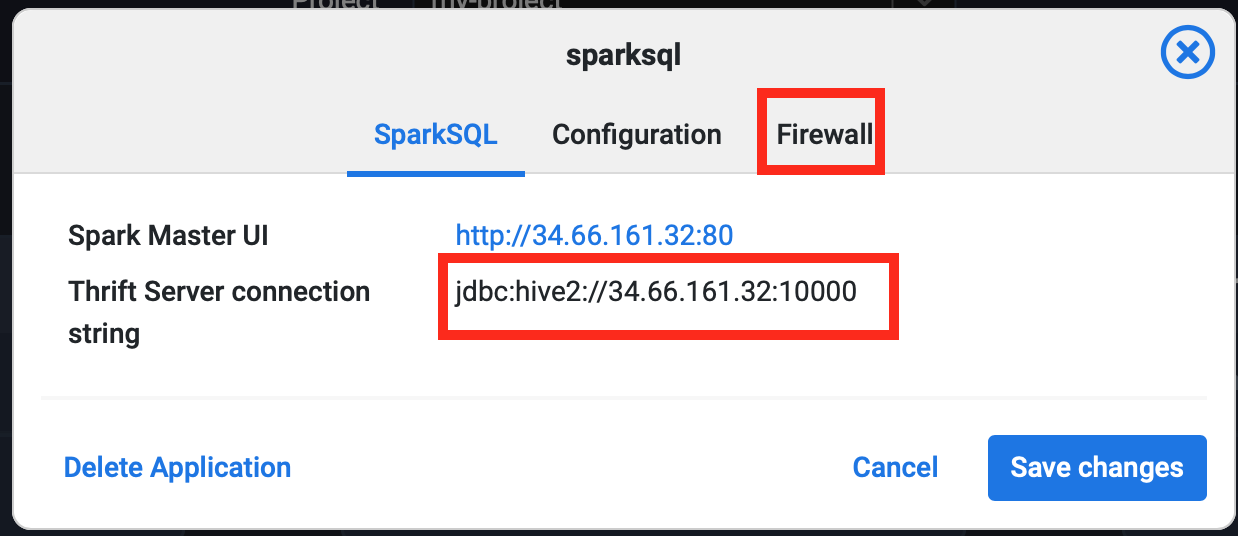
In the same dialogue, at the Firewall tab make sure your IP is white listed from your current location.
In DataGrip, click the "+" sign and add a Data Source by selecting the newly added Hive 1.2.1.
Paste the URL in the "URL" field. Click Test Connection.
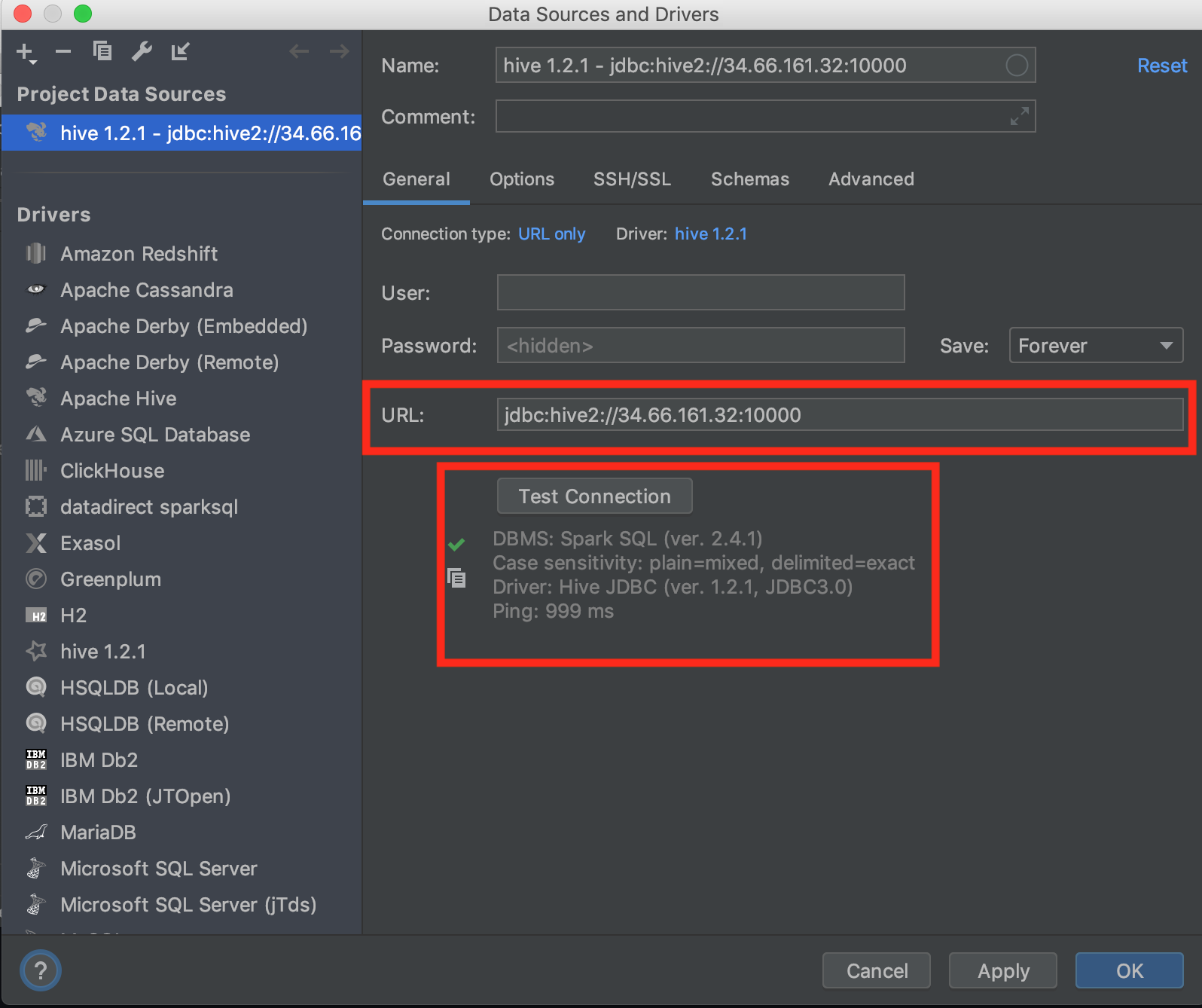
- If the test was successful click OK. If not, check your firewall settings at step 2.
You have now configured a data source.
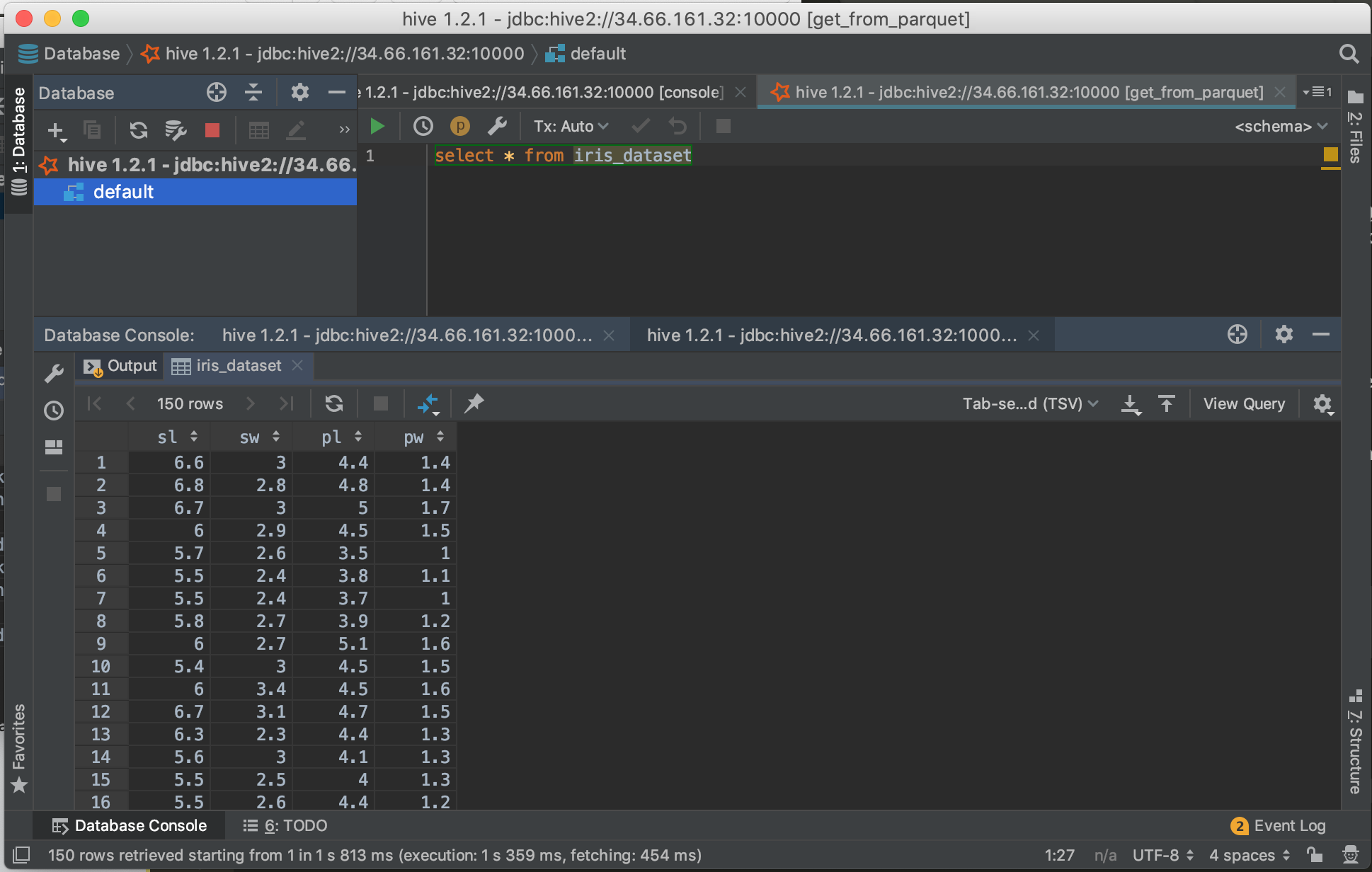
5. Query the datasets
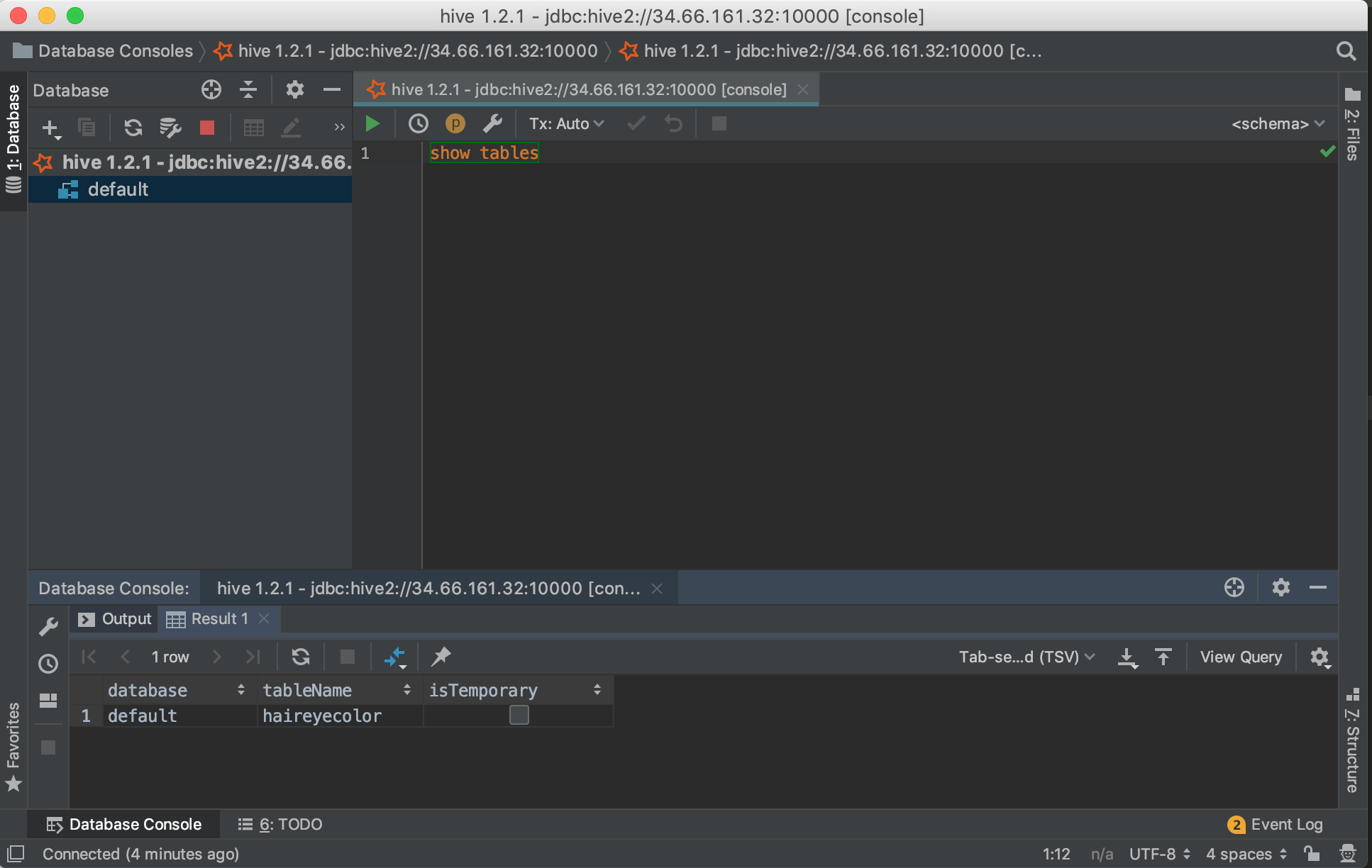
- Execute some queries on the connection:
SHOW TABLES
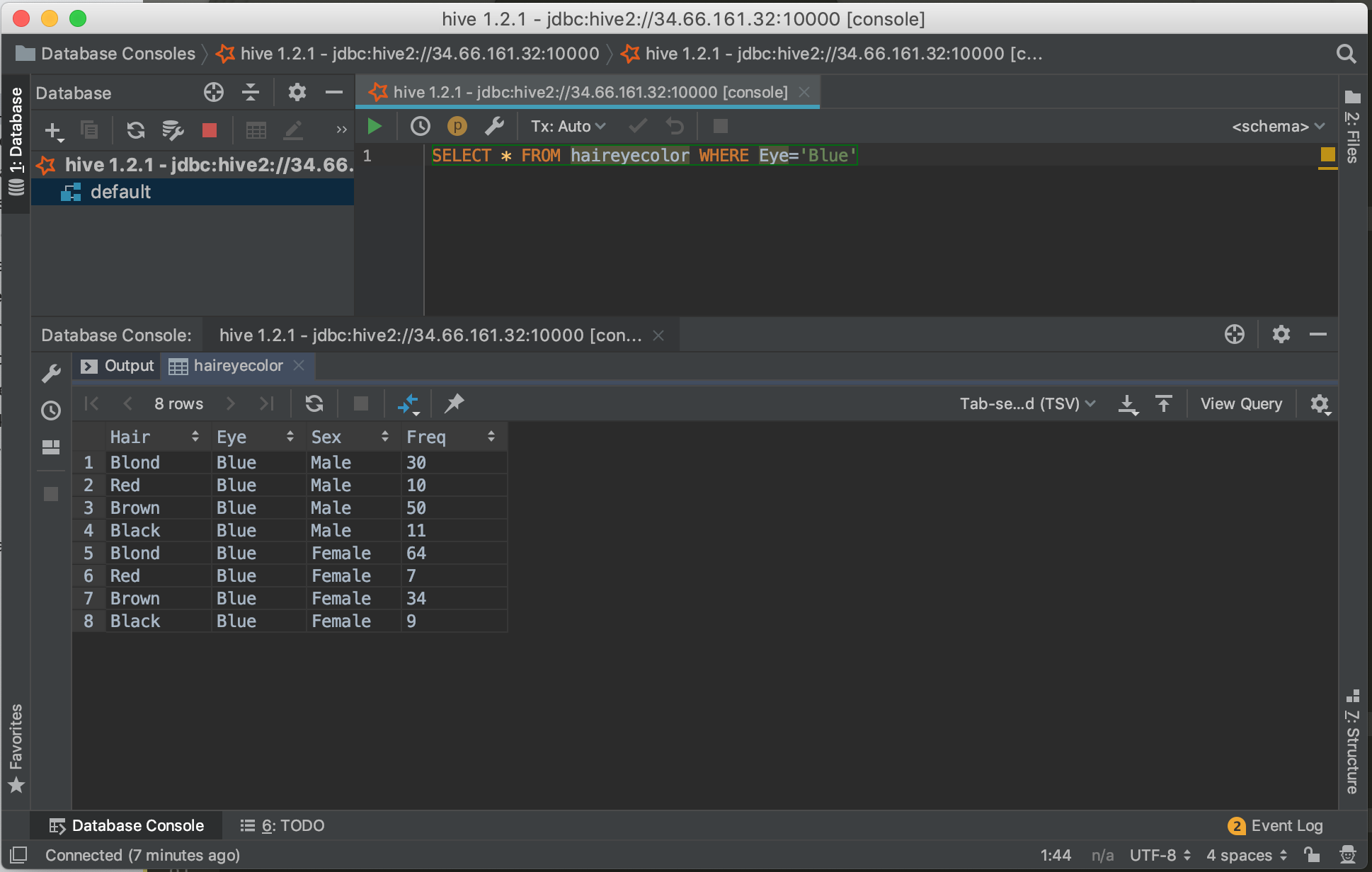
SELECT * FROM haireyecolor
Performance considerations
SparkSQL scales horizontally so if the performance is not satisfactory add more workers from SparkSQL's Configuration Tab. Depending on your use case you might need to add more RAM to support more complex joins.
Creating tables
Tables are created either through an import process using a Reusable Code Block, or created via a Jupyter notebook. In both situations they need to be "registered" in the metastore. To do so you need to execute Spark's saveAsTable() function.
Another option is to directly create the tables from external files (such as parquet or CSV) from the external SQL tool.
For example to create a new table execute a CREATE TABLE ... LOCATION command.
CREATE TABLE IF NOT EXISTS iris_dataset(`sl` double,`sw` double,`pl` double, `pw` double )
USING PARQUET
LOCATION '/datasets/iris-dataset.parquet'
To query the newly created table:
SELECT * from iris_dataset