Creating a docker image based reusable code block
To build a custom code block you will need to build an executable docker image and push in our repository or any Docker repository such as Dockerhub.
Write the code
We will use python in this example but you are free to use any programming language. The source code is available at github.
from os import getenv
from socket import gethostbyname, gethostname
from pyspark.sql import SparkSession,Row
from pyspark.mllib.random import RandomRDDs
SPARK_MASTER= getenv('SPARK_MASTER','local[2]')
OUTPUT_DIR=getenv('OUTPUT_DIR')
if(OUTPUT_DIR==None):
raise Exception('OUTPUT_DIR cannot be null');
spark = SparkSession.builder \
.appName("my_app") \
.config("spark.driver.host",gethostbyname(gethostname())) \
.master(SPARK_MASTER) \
.getOrCreate()
l=[('alex',25),('cristina',22),('sergiu',20),('john',26)]
rdd = spark.sparkContext.parallelize(l)
people = rdd.map(lambda x: Row(name=x[0], age=int(x[1])))
data = spark.createDataFrame(people)
data.write.mode("overwrite").save(OUTPUT_DIR);
Note the use of environment variables as arguments. They are preferred over input arguments. Our reusable code block framework will pass arguments as environment variables.
Note: When working with spark
Build the image
While any image is supported we recommend starting from our bigstepinc/jupyter_bdl image if developing python or java/scala applications as it is the same image that data scientists use. This will ensure that the various libraries have compatible versions. It also comes with the Lentiq Data Lake Libraries (jars) and their configuration that allow access to the storage layer.
The Dockerfile:
FROM bigstepinc/jupyter_bdl:2.4.1-1
RUN mkdir -p /myapp
ADD /myapp /myapp
ADD /codeblock-entrypoint.sh /codeblock-entrypoint.sh
ENTRYPOINT /codeblock-entrypoint.sh /myapp/my_test_program.py
Build the image:
docker build -t reusable_code_block_test:latest .
Test your code during development:
To test your code during development you will need to run your docker image and your application:
docker run -it -e OUTPUT_DIR="/tmp/output.parquet" -v /tmp:/tmp reusable_code_block_test:latest
Push your image to Dockerhub
Note that this needs to be a public repository, private repositories are not currently supported.
docker tag reusable_code_block_test <your_id>/reusable_code_block_test
docker push <your_id>/reusable_code_block_test
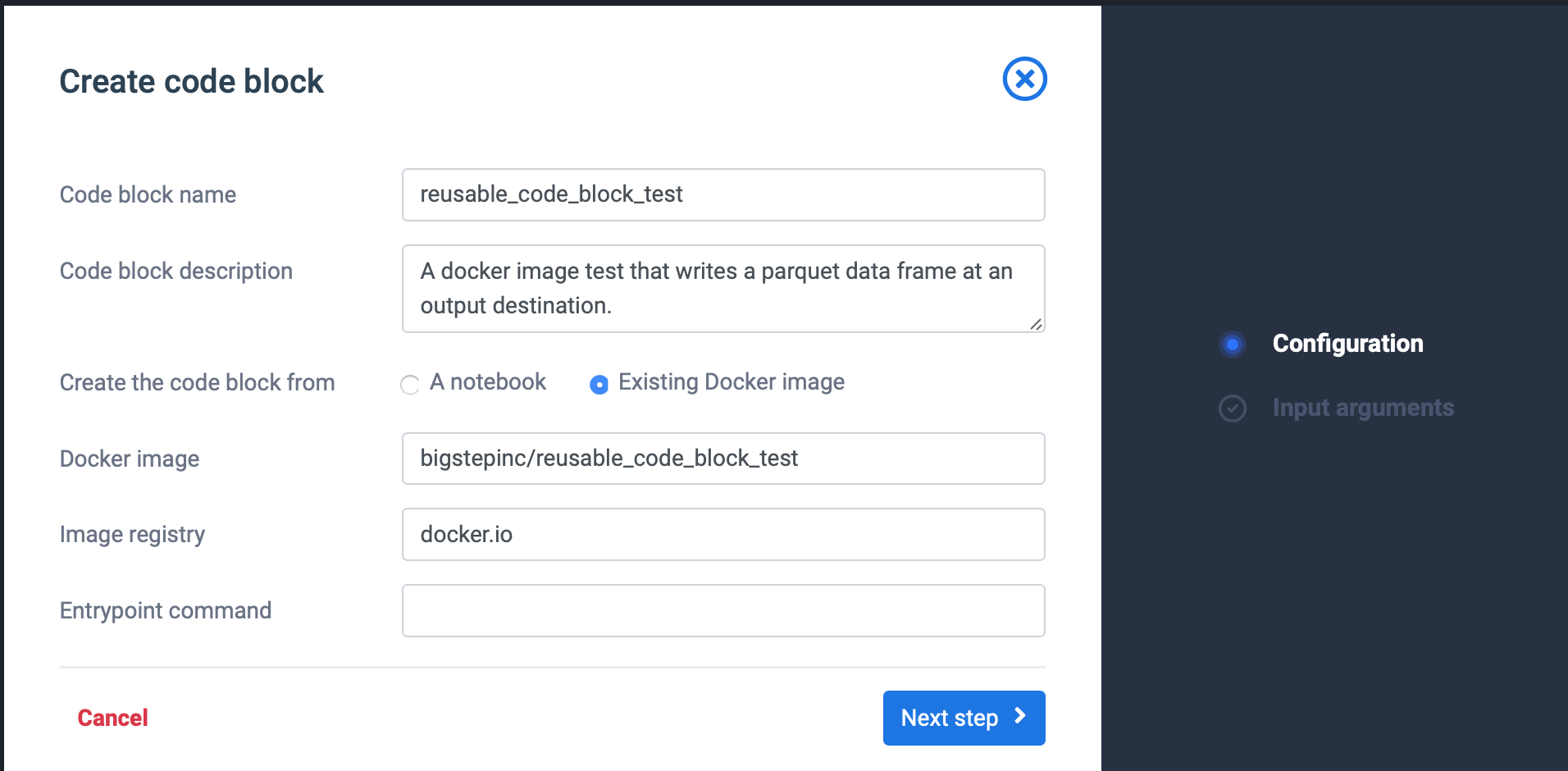
Use to create Reusable Code Block
Use the newly pushed docker image to create a new Docker image based Reusable Code Block.
- Input any name and description in the fields.
- Use docker.io as registry if using Dockerhub.
- The entrypoint for the docker image is typically already set in your docker image but if not set, you can set it here.
- Click Next
- For each input parameter (SPARK_MASTER and OUTPUT_DIR) add a parameter: Set required the flag only for the OUTPUT_DIR. Use the default values available in code and write a meaning full description.
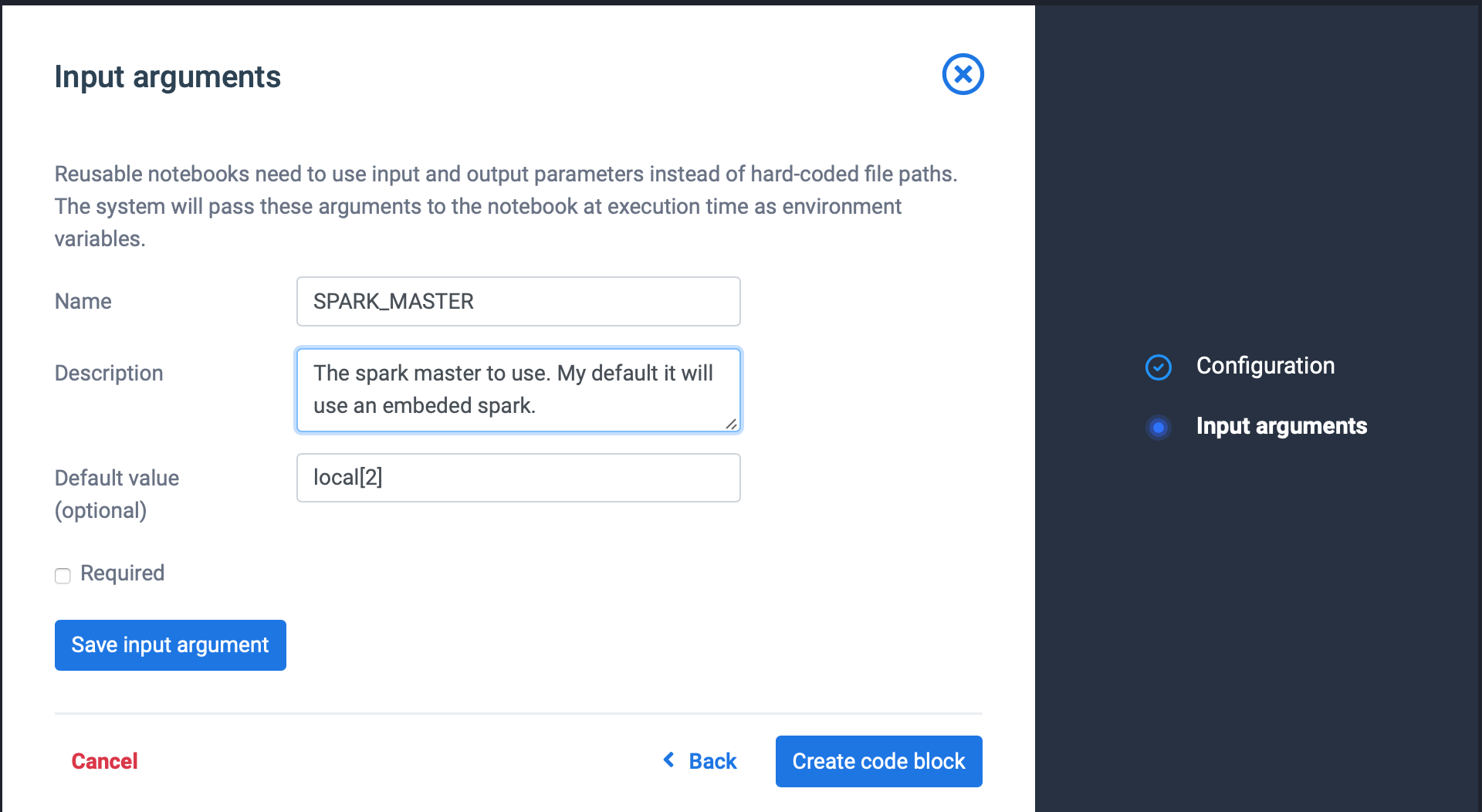
Click save input argument when ready. Repeat step 5 until you have specified all input arguments.
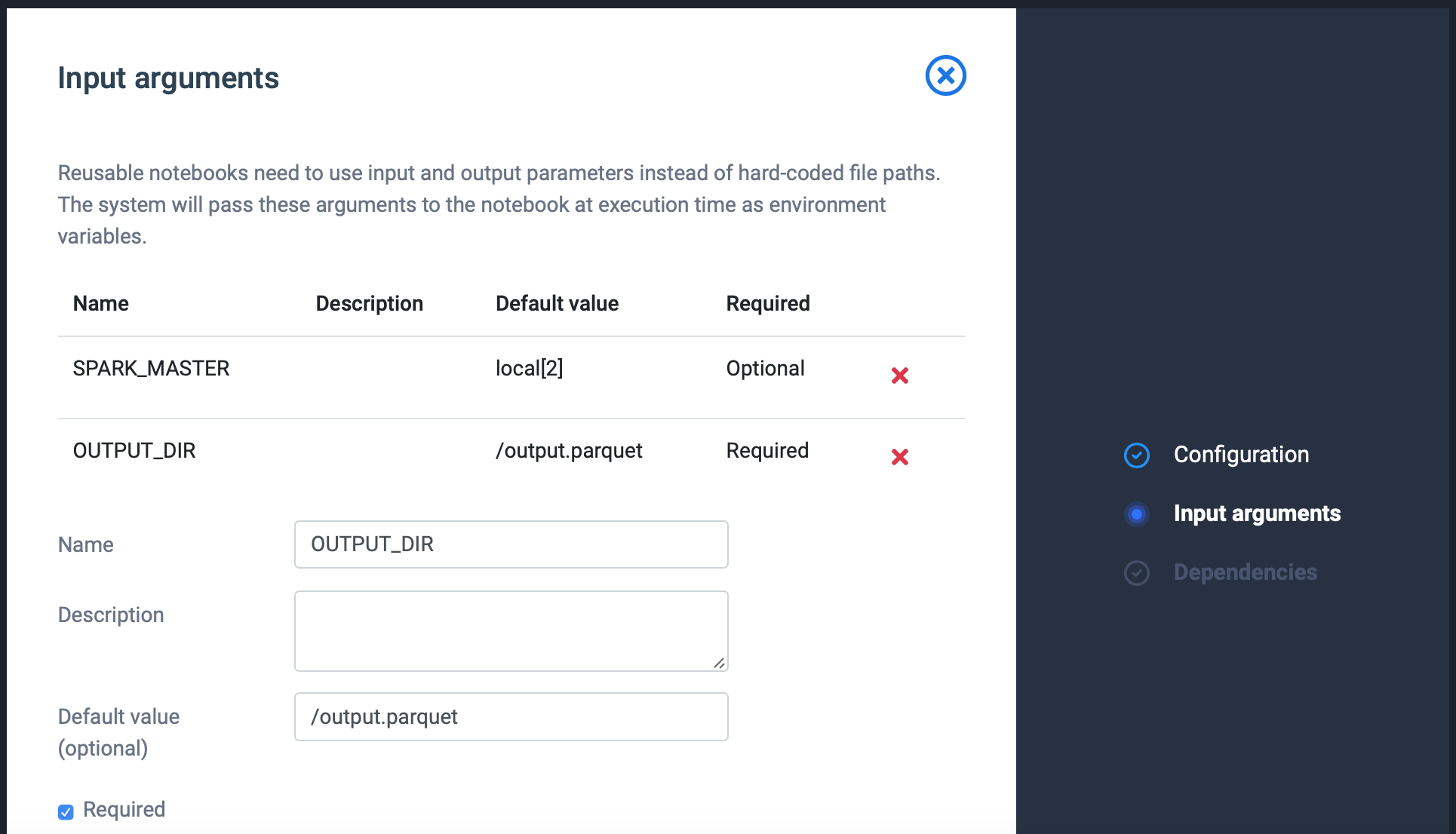
- Click Create Code Block