Managing model servers
Lentiq offers a Model Serving service that allows to present an inference API service to another application such as a website or some backoffice service.

Models are serialized using the MLeap format, stored in the object storage and loaded automatically by the model server at startup time.
Provision Lentiq's Model Server
The Model Server is a facility provided by Lentiq to execute and load-balance multiple model serving instances. The model server is thus highly available and scalable. The model server pre-loads the model configured in the user interface.
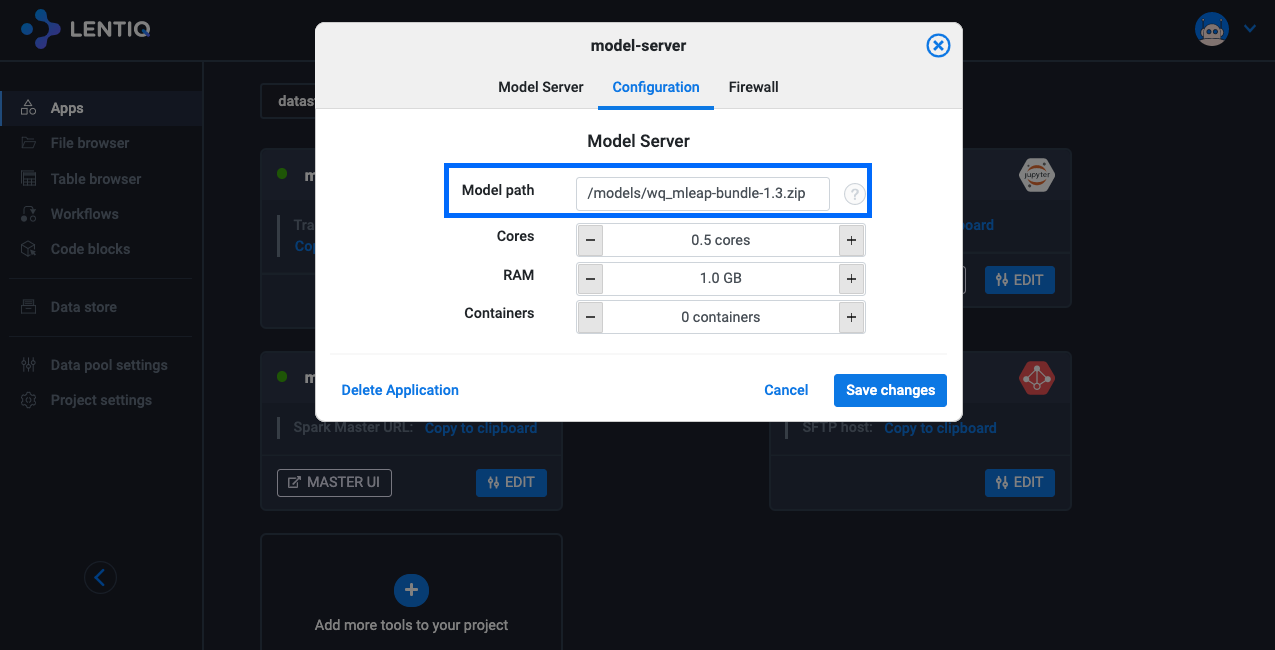
Lentiq's Model Server currently supports only the MLeap backend but more backends (eg: Tensorflow serving) will be added in the future.
Note: Not all transformers are supported by MLeap.
Scaling the Model Server
This service can be horizontally scaled to an unlimited number of "inference" instances. As the model server boots, the model specified in the params is pre-loaded and the /transform endpoint will be available.

Updating the model path, to a new model version will be done using a rolling update strategy which ensures no downtime during update.
Calling the inference API
Calling the API from any external application is very straightforward:
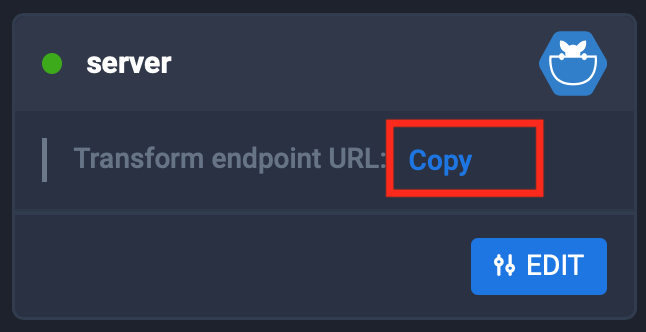
- Copy the transform URL from the Lentiq interface (after provisioning a model server and configuring it to load the model in the configuration tab).
- On your machine (mac or Linux) create a file called test.json:
{
"schema": {
"fields": [{
"name": "sl",
"type": "double"
}, {
"name": "sw",
"type": "double"
}, {
"name": "pl",
"type": "double"
}, {
"name": "pw",
"type": "double"
}]
},
"rows": [
[5.1, 3.8, 1.9, 0.4],
[6.7, 3.3, 5.7, 2.5],
[5.5, 2.4, 3.8, 1.1],
[6.3, 3.3, 6.0, 2.5],
[4.9, 2.5, 4.5, 1.7],
[6.7, 3.1, 5.6, 2.4],
[5.6, 2.7, 4.2, 1.3],
[5.7, 2.8, 4.1, 1.3],
[5.0, 3.3, 1.4, 0.2],
[5.8, 4.0, 1.2, 0.2]
]
}
- Execute a POST to the transform URL using the test.json payload:
curl -XPOST -H "accept: application/json" -H "content-type: application/json" -d @test.json 35.202.248.0:65327/transform
output:
{
"schema": {
"fields": [{
"name": "sl",
"type": "double"
}, {
"name": "sw",
"type": "double"
}, {
"name": "pl",
"type": "double"
}, {
"name": "pw",
"type": "double"
}, {
"name": "features",
"type": {
"type": "tensor",
"base": "double",
"dimensions": [4]
}
}, {
"name": "rawPrediction",
"type": {
"type": "tensor",
"base": "double",
"dimensions": [3]
}
}, {
"name": "probability",
"type": {
"type": "tensor",
"base": "double",
"dimensions": [3]
}
}, {
"name": "prediction",
"type": {
"type": "basic",
"base": "double",
"isNullable": false
}
}]
},
"rows": [[5.1, 3.8, 1.9, 0.4, {
"values": [5.1, 3.8, 1.9, 0.4],
"dimensions": [4]
}, {
"values": [19.0, 1.0, 0.0],
"dimensions": [3]
}, {
"values": [0.95, 0.05, 0.0],
"dimensions": [3]
}, 0.0], [6.7, 3.3, 5.7, 2.5, {
"values": [6.7, 3.3, 5.7, 2.5],
"dimensions": [4]
}, {
"values": [0.0, 0.0, 20.0],
"dimensions": [3]
}, {
"values": [0.0, 0.0, 1.0],
"dimensions": [3]
}, 2.0], [5.5, 2.4, 3.8, 1.1, {
"values": [5.5, 2.4, 3.8, 1.1],
"dimensions": [4]
}, {
"values": [0.0, 20.0, 0.0],
"dimensions": [3]
}, {
"values": [0.0, 1.0, 0.0],
"dimensions": [3]
}, 1.0], [6.3, 3.3, 6.0, 2.5, {
"values": [6.3, 3.3, 6.0, 2.5],
"dimensions": [4]
}, {
"values": [0.0, 0.0, 20.0],
"dimensions": [3]
}, {
"values": [0.0, 0.0, 1.0],
"dimensions": [3]
}, 2.0], [4.9, 2.5, 4.5, 1.7, {
"values": [4.9, 2.5, 4.5, 1.7],
"dimensions": [4]
}, {
"values": [0.0, 15.875, 4.125],
"dimensions": [3]
}, {
"values": [0.0, 0.79375, 0.20625],
"dimensions": [3]
}, 1.0], [6.7, 3.1, 5.6, 2.4, {
"values": [6.7, 3.1, 5.6, 2.4],
"dimensions": [4]
}, {
"values": [0.0, 0.0, 20.0],
"dimensions": [3]
}, {
"values": [0.0, 0.0, 1.0],
"dimensions": [3]
}, 2.0], [5.6, 2.7, 4.2, 1.3, {
"values": [5.6, 2.7, 4.2, 1.3],
"dimensions": [4]
}, {
"values": [0.0, 20.0, 0.0],
"dimensions": [3]
}, {
"values": [0.0, 1.0, 0.0],
"dimensions": [3]
}, 1.0], [5.7, 2.8, 4.1, 1.3, {
"values": [5.7, 2.8, 4.1, 1.3],
"dimensions": [4]
}, {
"values": [0.0, 20.0, 0.0],
"dimensions": [3]
}, {
"values": [0.0, 1.0, 0.0],
"dimensions": [3]
}, 1.0], [5.0, 3.3, 1.4, 0.2, {
"values": [5.0, 3.3, 1.4, 0.2],
"dimensions": [4]
}, {
"values": [20.0, 0.0, 0.0],
"dimensions": [3]
}, {
"values": [1.0, 0.0, 0.0],
"dimensions": [3]
}, 0.0], [5.8, 4.0, 1.2, 0.2, {
"values": [5.8, 4.0, 1.2, 0.2],
"dimensions": [4]
}, {
"values": [20.0, 0.0, 0.0],
"dimensions": [3]
}, {
"values": [1.0, 0.0, 0.0],
"dimensions": [3]
}, 0.0]]
}
What this last call did was: "Given a series of input rows of features (such as [5.1, 3.8, 1.9, 0.4]) which in this example are the sepal width and height etc from the iris flower dataset, categorize the type of flower.
The model's inference is in the last value in the array. There are 3 classes so the values will be 0.0,1.0 or 2.0 ('Iris setosa', 'Iris virginica' and 'Iris versicolor'):
[5.1, 3.8, 1.9, 0.4, {...}, 0.0] # the model thinks this is 'iris setosa'
[5.7, 2.8, 4.1, 1.3, {...}, 1.0] # the model thinks this is 'iris virginica'
Warning: there is no authentication on this service. Use the firewall feature to restrict access from secure backend servers.
Deploying the latest model programatically
If you re-train your model you will want to update the model in production. To do that you need to issue an API call to Lentiq to tell it to update the model. Note that this is a different API (Lentiq's application management API) than the inference API (model server's transform API) that we discussed earlier.
- Get your API key from the Lentiq interface.
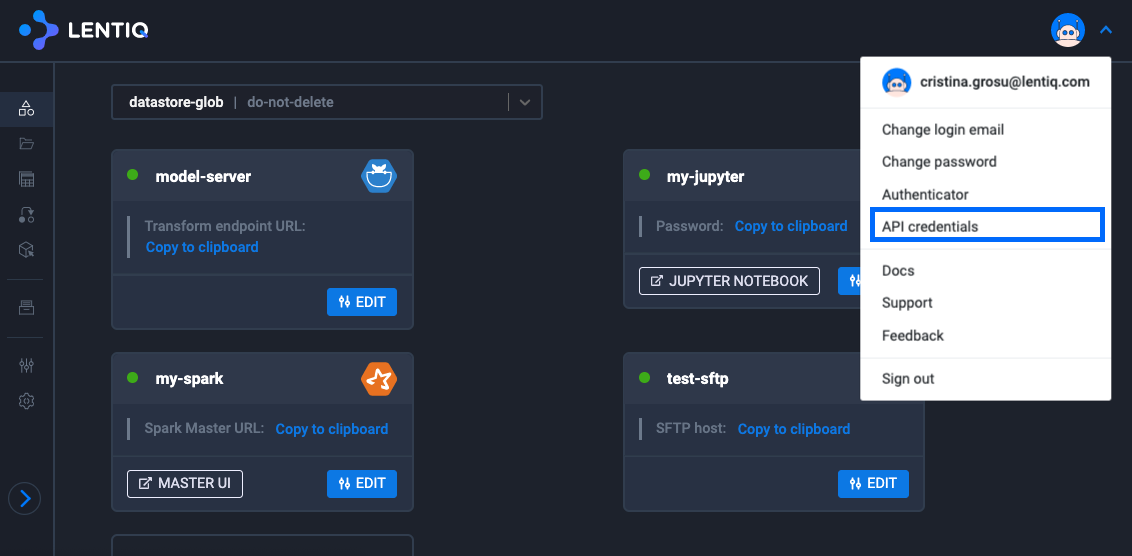
- Use that API key to execute a call to the Lentiq's Application API. Copy paste this into a cell in a notebook and replace your API key with the proper one.
#update these values to match your environment
#get your api key from the Lentiq application, it is available in your account details.
api_key=""
if(api_key==""):
raise Exception("get your api key from the Lentiq UI")
#This is the URL where the model bundle was uploaded. eg: /models/mleap-bundle-1.4.zip".
model_path=""
#this is the name of the model serving application. Get this from the Dashboard
application_name = "modelsrv"
import os
import requests
import json
import sys
data_pool_name = os.environ['DATAPOOL_NAME']
project_name = os.environ['PROJECT']
endpoint=os.environ['API_ENDPOINT']+'/api/v1'
#prepare our url and auth headers
headers = {'Authorization': "APIKEY "+api_key}
url = "{}/applications/{}/{}/{}".format(endpoint, data_pool_name, project_name, application_name)
print("Calling GET {}".format(url))
app=requests.get(url, headers=headers).json()
app['configuration']['modelPath'] = model_path
print("Calling PUT {}".format(url))
#update model
r=requests.put(url, headers=headers, json=app['configuration'])
if(r.status_code!=200):
print('Something went wrong! Server returned:'+r.content.decode("UTF-8"))
- Verify that the model's path has been updated to the new version in the UI.
Benchmarking the model server's performance using apache benchmark
The simplest test you can do to measure the performance of your model server is to use apache benchmark ab utility. This tool comes with MacOS X but can also be installed as part of the apache http server tools suite. Using the same json content execute 10 concurent streams of request until a total count of 1000 requests is executed:
ab -p test.json -T application/json -l -c 10 -n 1000 34.66.9.18:65327/transform
This is ApacheBench, Version 2.3 <$Revision: 1826891 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 34.66.9.18 (be patient)
Completed 100 requests
Completed 200 requests
Completed 300 requests
Completed 400 requests
Completed 500 requests
Completed 600 requests
Completed 700 requests
Completed 800 requests
Completed 900 requests
Completed 1000 requests
Finished 1000 requests
Server Software: akka-http/10.0.3
Server Hostname: 34.66.9.18
Server Port: 65327
Document Path: /transform
Document Length: Variable
Concurrency Level: 10
Time taken for tests: 31.624 seconds
Complete requests: 1000
Failed requests: 0
Total transferred: 3174000 bytes
Total body sent: 538000
HTML transferred: 3019000 bytes
Requests per second: 31.62 [#/sec] (mean)
Time per request: 316.238 [ms] (mean)
Time per request: 31.624 [ms] (mean, across all concurrent requests)
Transfer rate: 98.01 [Kbytes/sec] received
16.61 kb/s sent
114.63 kb/s total
Connection Times (ms)
min mean[+/-sd] median max
Connect: 134 150 107.9 136 1162
Processing: 137 160 140.5 141 4113
Waiting: 137 157 134.8 140 3978
Total: 272 311 200.4 277 4834
Percentage of the requests served within a certain time (ms)
50% 277
66% 278
75% 281
80% 291
90% 318
95% 372
98% 857
99% 1309
100% 4834 (longest request)
Note: the -l from the request is important if you update your model mid-test as the length of the content will change after the model is updated which is fine for a client but ab would otherwise interpret that as being a failed request.