Sharing data between data pools
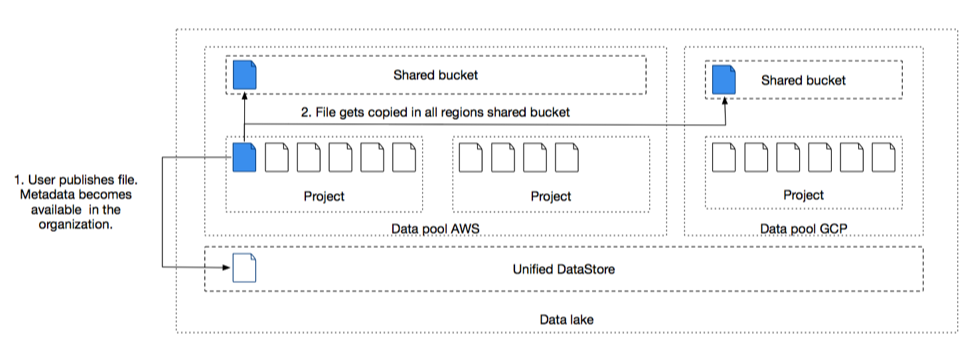
The publish subscribe mechanism is the one that brings data pool together at the data level creating a centralized view of the "virtual data lake". In order to be able to collaborate between multiple data pools and projects, organizations can use the publish/subscribe mechanism for data relevant to the entire organization that needs to be shared to be used by other departments, business units, use cases.
By default all users have access to:
- all data stored in a project where they have access to through the "File Browser"
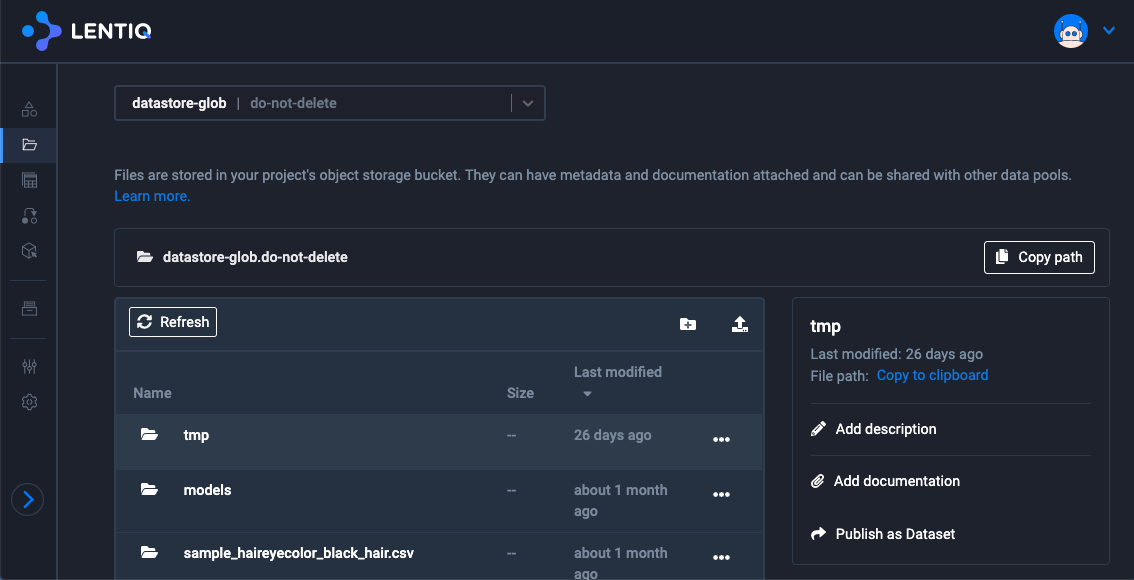
- all data that has been published in the organization through the data store
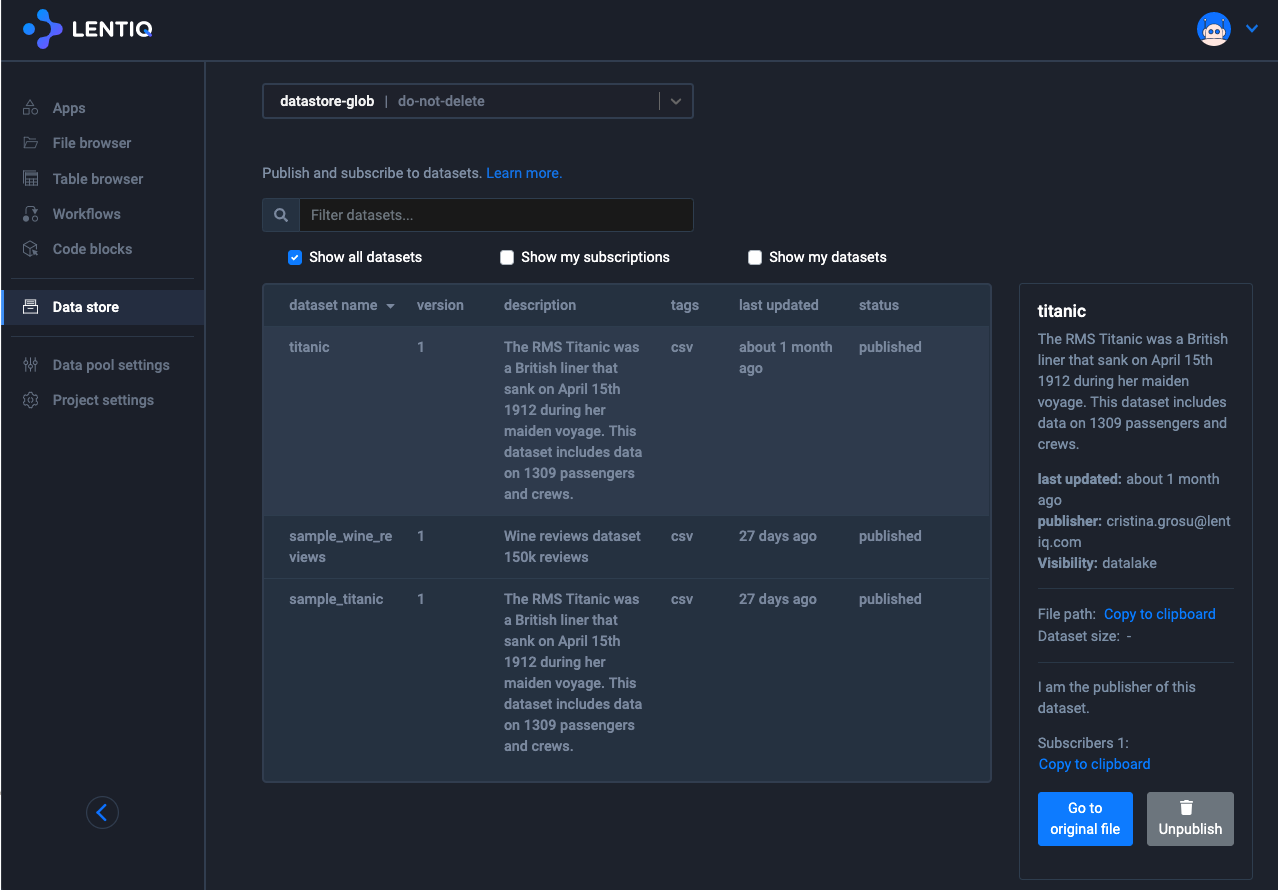
Publishing data
Only users that have publishing rights are allowed to publish data to the rest of the organization. The data pool administrator, or the project manager can grant publishing rights to users. By limiting the number of users that have publishing rights, project administrators can define internally some publishing policies and can maintain control of sensitive data.
Once a dataset is published, a very clear documentation process has to be followed. Governance at the centralized data store level is enforced through the publishing mechanism. In this manner users have the maximum flexibility at project level, while also maintaining a standardized documentation process at the extended data lake level.
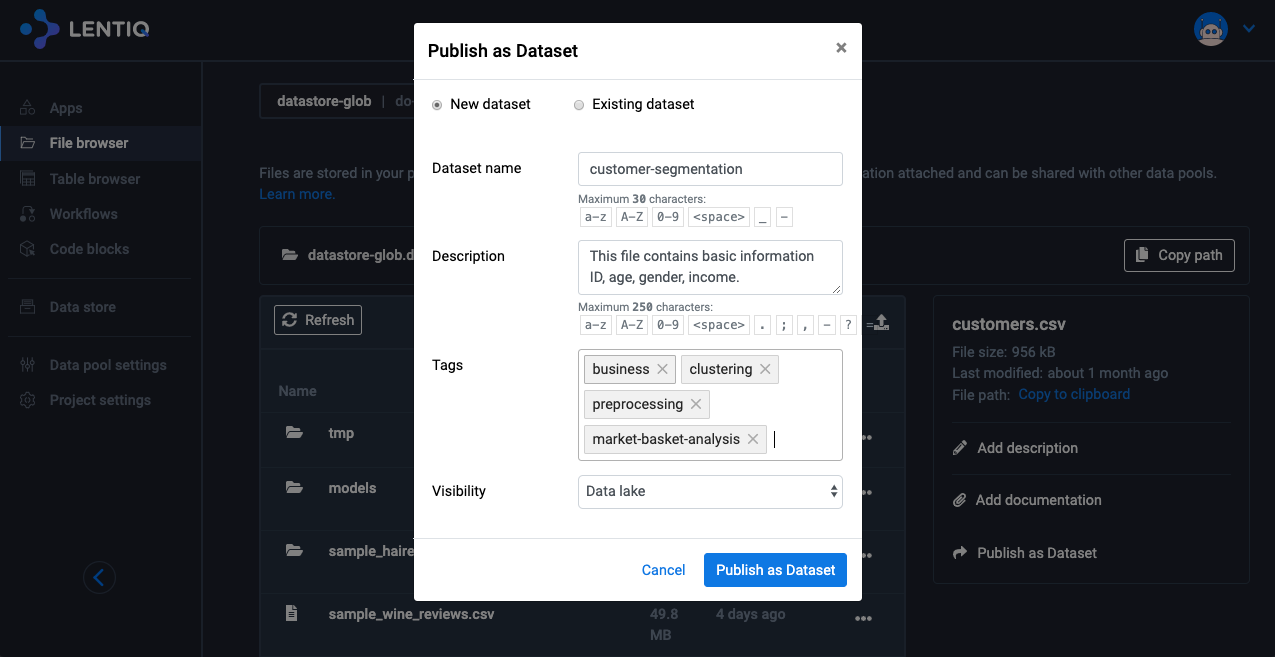
Once datasets are published, they become part of the centralized data store where all users have access. These data sets are very well documented, and users can subscribe to these datasets to receive updates when the content or structure is changing. Published datasets live in a global data space where they can be very easily accessed via simple read operations.
Subscribing to a dataset
All users that are part of a project can subscribe to datasets that are publicly available for the organization. The users can see a sample of the datasets that are available, but only when subscribing, they have full read access to the dataset and to notifications related to it.
If the subscriber wants to edit the dataset, the subscriber can fetch a copy of the dataset and place it to a project where she has access to.
Notifications will be automatically be sent via email to all subscribers to a dataset when metadata has been modified, when data has been added/deleted, when the structure has been changed or when a new version has appeared.
Based on the nature of the notification, the subscriber can decide what actions to perform: ignore notification, override current version or download the new version and keep the old one as well.