Working with workflows
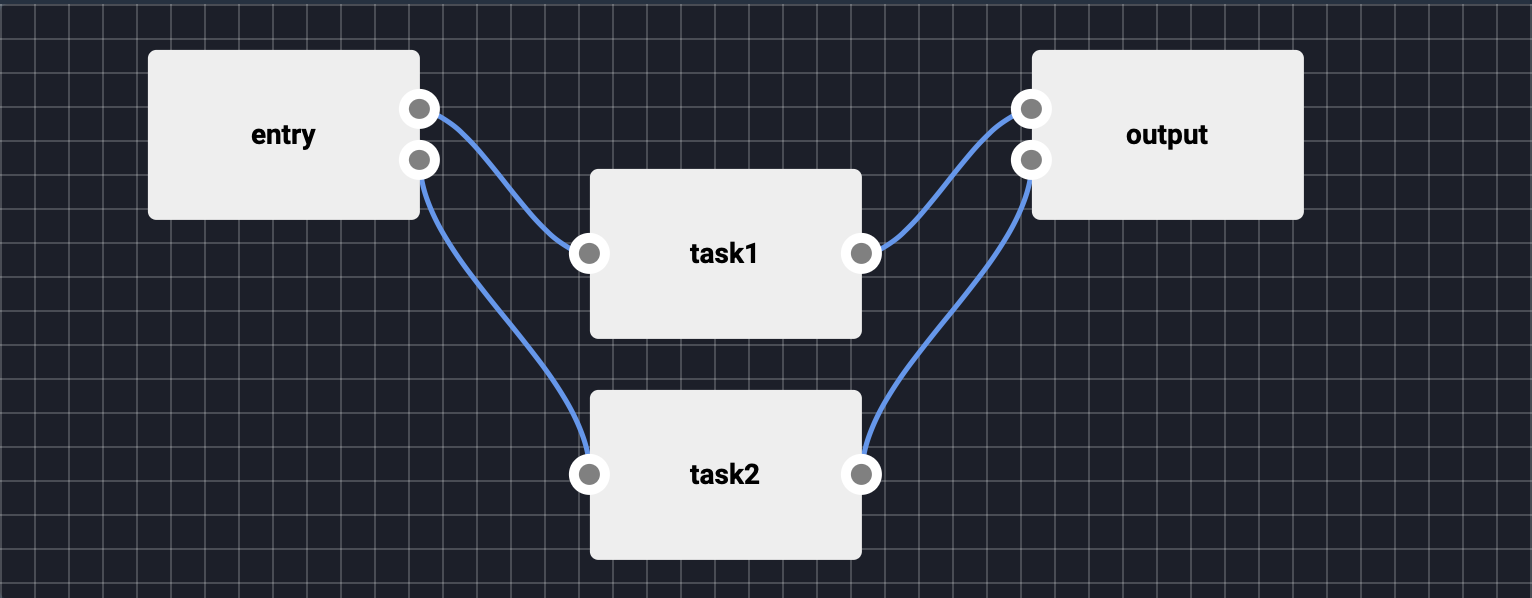
The Lentiq Workflow engine is designed to perform periodic tasks such model training, data processing, data cleaning, ETL etc. Workflows are graphs of instances of Reusable Code Blocks that can be scheduled to be executed at a certain date and repeat with a certain periodicity.
Reusable Code Blocks
You can think about a Reusable Code Block as a template for creating Tasks. Behind a Reusable Code Block there is a Docker container that can be either automatically generated by Lentiq by packaging a Notebook and it's dependencies or a user's custom Docker image.
Users typically package frequent tasks such as cleaning data, anonymizing data, training models etc.
Reusable code blocks are shared with the entire data lake and are stored in Lentiq's global registry. This means that any user of any data pool within the same data lake can leverage this Reusable Code Block once it has been created to perform similar tasks.
Tasks
Workflows are built with Tasks. Each task is an instance of a Reusable Code Block that is, the input variables of the Reusable Code Block are configured to match the environment and requirements of the user. Several more environment variables are passed to the Task at run time that include for instance the API key for accessing the data pool which is interpreted by Lentiq's file access layer.
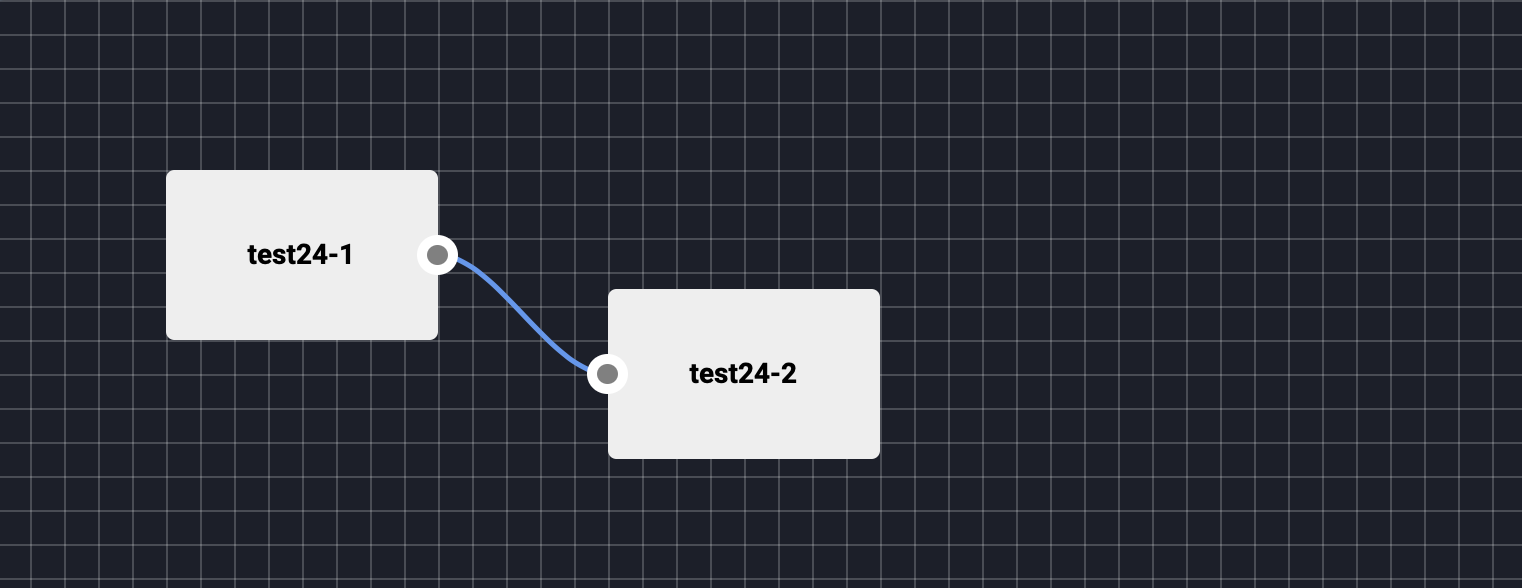
Tasks can also have as dependencies other tasks. A task will wait for the other task to be executed before starting.
For instance task test24-2 has as input dependency task test24-1:
Tasks can run for any amount of time, there is no timeout.
Resource management
Tasks have associated an amount CPU and RAM that they will ask the service to deliver when they need to execute. If the current project does not have enough resources available the Task will stay in a "PENDING" state until enough resources are freed up. Make sure that the project has enough resources configured to cover the execution of the workflow or create a separate project for the workflows.
Scheduler
Every 30 seconds the Scheduler checks to see if there are available workflows and will start the execution immediately if the date is set in the past. The scheduler will not execute a new run of a workflow if there is another one pending or running.