Working with data and metadata
The data management layer protects your data lake from becoming a data swamp. Each file or Table that is stored in the data lake can be documented so that yourself and your team can make sense of it later.
The data management layer can be used both through the API and GUI to increase the pool of potential users. This democratizes access to data across the organization and increases the chances of the data lake actually being used to achieve its initial results.
Accessing data in Lentiq
There are many ways to access the data in Lentiq but fundamentally it is through two mechanisms:
- Uploading/downloading/accessing files to and from the Data Pool's Object Storage (you can upload CSVs but also Images or PDFs etc). You can do this through many ways. Checkout this tutorial for more information on how to do that.
- Querying data using SQL. Structured data can be "registered" in Lentiq to appear as Tables. This allows you to query it using an external SQL or BI tool or from inside a notebook.
Structured data is stored in Parquet format for quick retrieval. Accessing data in this format is faster and occupies less space than CSVs.
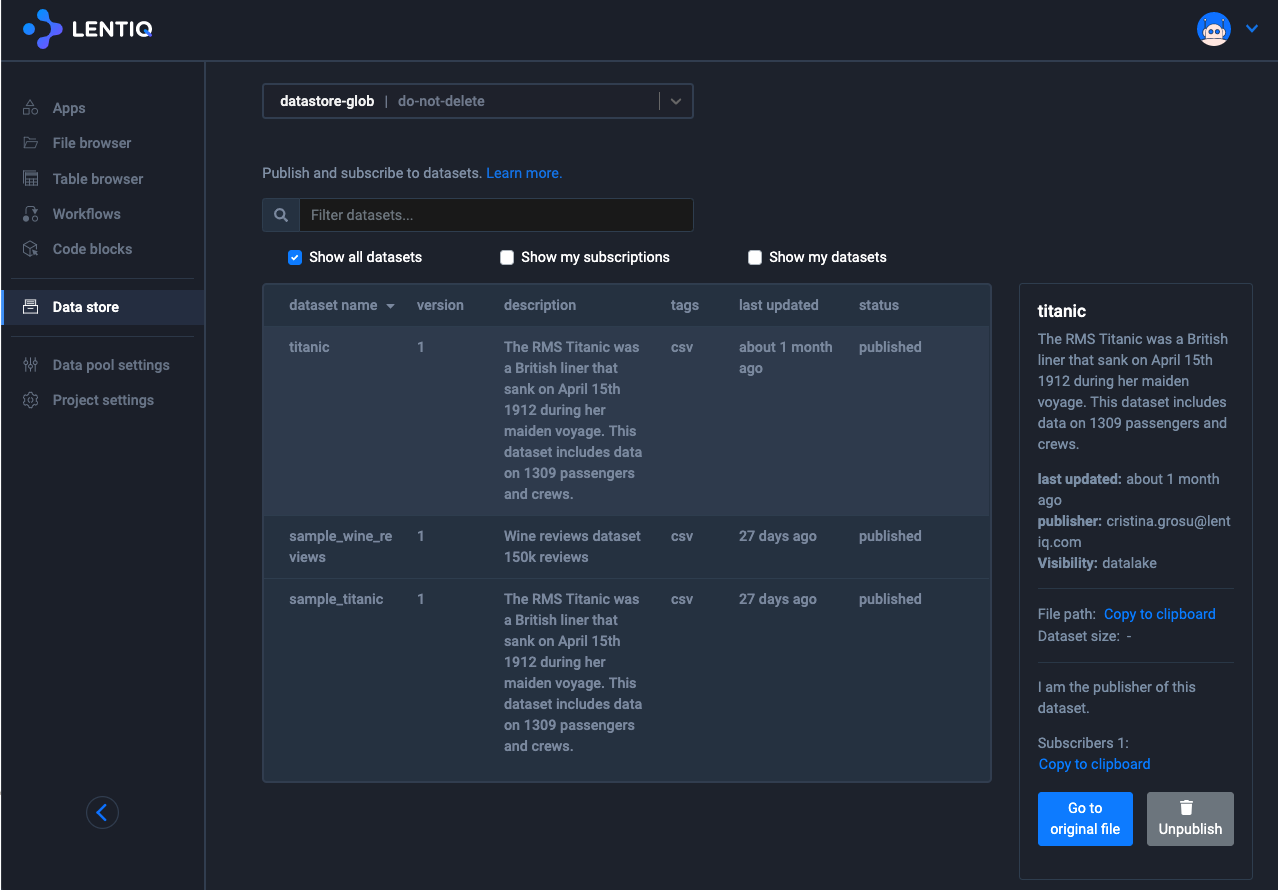
Localized and centralized metastore
Each data lake comes with a central metastore. In this metastore we generally store metadata information on datasets and tables that have been shared across the organization. When users interact with the Data Store the central metastore is queried.
Each data pool has a shared bucket entirely managed by Lentiq. By default, all users with access to a project have read access to this bucket. In this bucket all published datasets that have been published in the organization are stored.
Each project has a local metastore. This metastore is used only for metadata information on the data stored in that particular project. This increases the flexibility at project level and makes sure that sudden changes at project level do not interfere with the central metastore. The local metastore is pre-configured to have access to the bucket assigned to a particular project. When users interact with files and tables through Spark that are strictly stored within the project, the users are performing data modelling through this local metastore.
The local metastore cannot be accessed directly by the users. However, they can access data in the object storage and analyze the associated tables using a JDBC connector that can be provisioned from the set of curated applications. This connector uses Spark Thrift Server behind the scenes.
Unified file system interface
The data management layer abstracts away all complexity of the underlying object storage, and exposes a unified file system interface. Users do not have to use the cloud provider file system schema when trying to access objects in the object storage. They can use directly our abstraction layer, that simplifies running the same workload on multiple cloud providers since there is no need of changing the file system schema.
To increase the flexibility of interacting with the storage layer, Lentiq provides a CLI controller that works similar to hadoop CLI. In this manner, ingestion scripts can be updated to send their data in the cloud very easily.
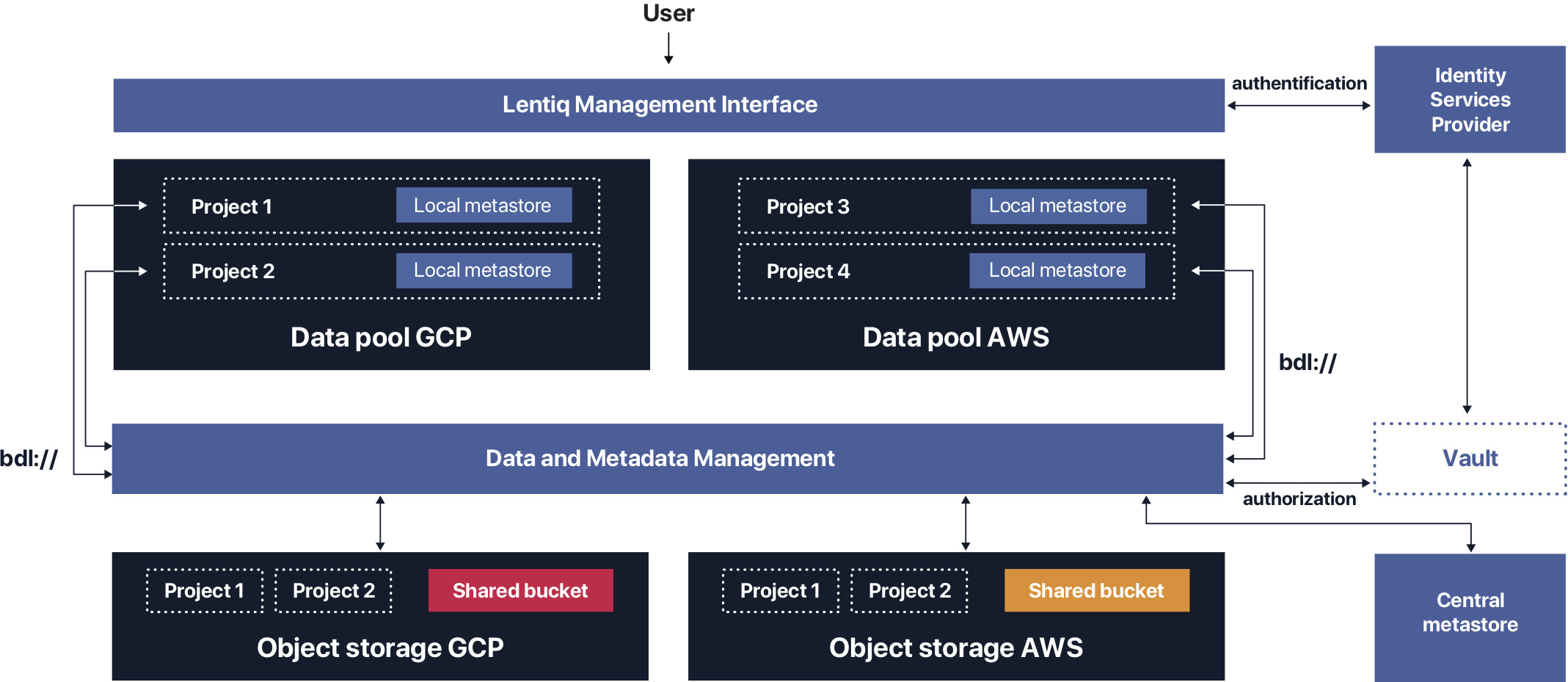
File browser
Lentiq provides the user the possibility to browse through all files and folders the user has access to. For each file, the user can see the documentation of the files he has access to. This documentation consists of attachments and descriptions. In addition, the user can download the file, access its contents or move the file to a different location.
The same user interface can be used to upload data in a specific project. Users can drag and drop files, attachments, in the UI and the upload process happens in the background. Once the upload is complete, files are readily accessible to the rest of the project.
File level data documentation
If there is no documentation, the user has the possibility to add documentation and to contribute to the data curation process. For files and directories, users can add attachments as well as configure the description.
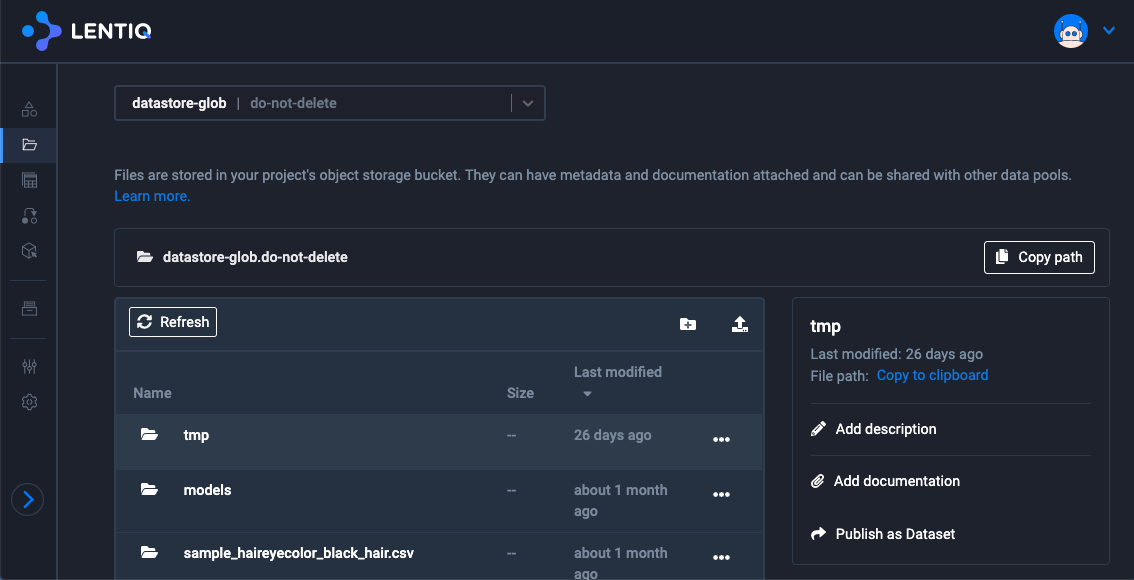
Table browser
Lentiq provides the user the possibility to browse through all tables the user has access to. For each table, the user can see the documentation of the tables, their schema, column documentation, column tags, table analytics. This documentation consists of attachments, descriptions or comments.
Tables are created through Spark jobs from the Jupyter Notebook application.
Table level data documentation
If there is no documentation, the user has the possibility to add documentation and to contribute to the table curation process. For tables, users can add table description, column descriptions, column tags.
Centralized Data Store
The centralized data store contains meta-data information on all published datasets and provides a unified user interface across the entire data lake for easier access to a central data repository. This links together all projects and data pools, forming a "virtual data lake" view.
This data store becomes the internal promoter of data inside your organization and based on the fact that data is highly documented helps increase its usage. It is a lot more easier for users in separated divisions to understand what the data is and how to use it in their day to day job.